为了学好Golang底层知识,折腾了一下编译器相关知识。下面的内容并不会提升你的生产技能点,但可以提高你能力指数。
认识 go build
当我们敲下 go build 的时候,我们的写的源码文件究竟经历了哪些事情?最终变成了可执行文件。
这个命令会编译go代码,今天就来一起看看go的编译过程吧!
首先先来认识以下go的代码源文件分类
- 命令源码文件:简单说就是含有 main 函数的那个文件,通常一个项目一个该文件,我也没想过需要两个命令源文件的项目 测试源码文件:就是我们写的单元测试的代码,都是以 _test.go 结尾 库源码文件:没有上面特征的就是库源码文件,像我们使用的很多第三方包都属于这部分
go build 命令就是用来编译这其中的 命令源码文件 以及它依赖的 库源码文件。下面表格是一些常用的选项在这里集中说明以下。
| 可选项 | 说明 |
|---|---|
| -a | 将命令源码文件与库源码文件全部重新构建,即使是最新的 |
| -n | 把编译期间涉及的命令全部打印出来,但不会真的执行,非常方便我们学习 |
| -race | 开启竞态条件的检测,支持的平台有限制 |
| -x | 打印编译期间用到的命名,它与 -n 的区别是,它不仅打印还会执行 |
接下来就用一个 hello world 程序来演示以下上面的命令选项。

如果对上面的代码执行 go build -n 我们看一下输出信息:
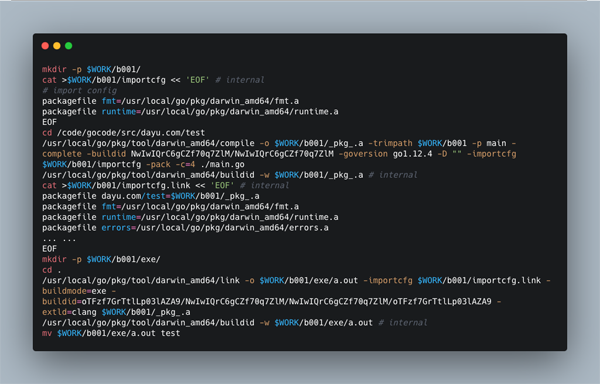
来分析下整个执行过程
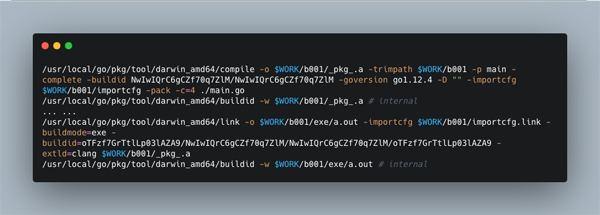
这一部分是编译的核心,通过 compile、 buildid、 link 三个命令会编译出可执行文件 a.out。
然后通过 mv 命令把 a.out 移动到当前文件夹下面,并改成跟项目文件一样的名字(这里也可以自己指定名字)。
文章的后面部分,我们主要讲的就是 compile、 buildid、 link 这三个命令涉及的编译过程。
编译器原理
这是go编译器的源码路径
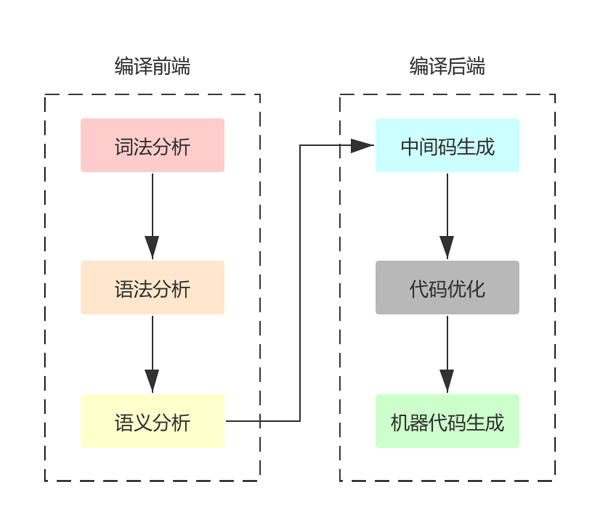
如上图所见,整个编译器可以分为:编译前端与编译后端;现在我们看看每个阶段编译器都做了些什么事情。先来从前端部分开始。
词法分析
词法分析简单来说就是将我们写的源代码翻译成 Token,这是个什么意思呢?
为了理解 Golang 从源代码翻译到 Token 的过程,我们用一段代码来看一下翻译的一一对应情况。
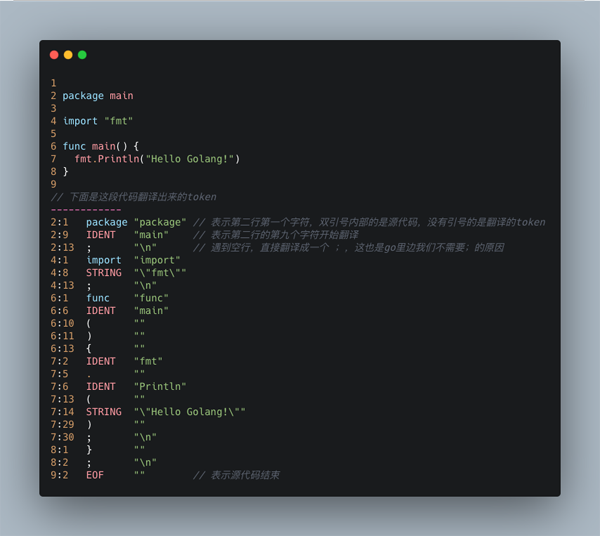
图中重要的地方我都进行了注释,不过这里还是有几句话多说一下,我们看着上面的代码想象以下,如果要我们自己来实现这个“翻译工作”,程序要如何识别 Token 呢?
首先先来给Go的token类型分个类:变量名、字面量、操作符、分隔符以及关键字。我们需要把一堆源代码按照规则进行拆分,其实就是分词,看着上面的例子代码我们可以大概制定一个规则如下:
识别空格,如果是空格可以分一个词; 遇到 ( 、)、'<‘、’>’ 等这些特殊运算符的时候算一个分词; 遇到 ” 或者 数字字面量算分词。
通过上面的简单分析,其实可以看出源代码转 Token 其实没有非常复杂,完全可以自己写代码实现出来。当然也有很多通过正则的方式实现的比较通用的词法分析器,像 Golang 早期就用的是 lex,在后面的版本中才改用了用go来自己实现。
语法分析
经过词法分析后,我们拿到的就是 Token 序列,它将作为语法分析器的输入。然后经过处理后生成 AST 结构作为输出。
所谓的语法分析就是将 Token 转化为可识别的程序语法结构,而 AST 就是这个语法的抽象表示。构造这颗树有两种方法。
1. 自上而下
这种方式会首先构造根节点,然后就开始扫描 Token,遇到 STRING 或者其它类型就知道这是在进行类型申明,func 就表示是函数申明。就这样一直扫描直到程序结束。
2. 自下而上
这种是与上一种方式相反的,它先构造子树,然后再组装成一颗完整的树。
go语言进行语法分析使用的是自下而上的方式来构造 AST,下面我们就来看一下go语言通过 Token 构造的这颗树是什么样子。
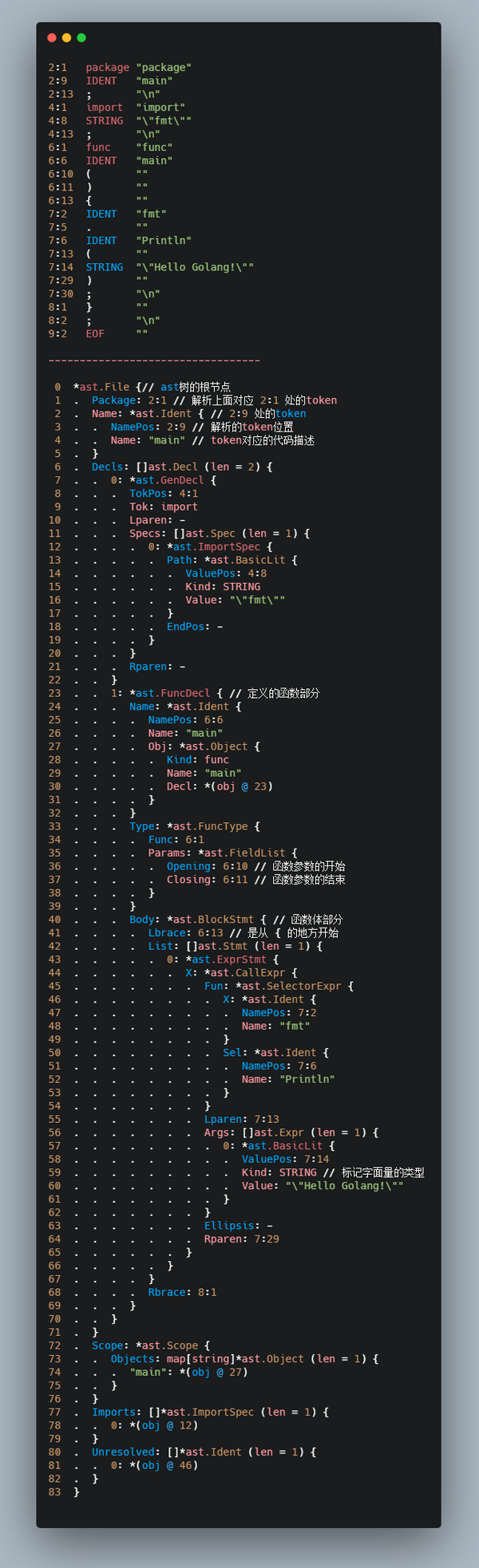
这其中有意思的地方我全部用文字标注出来了。你会发现其实每一个 AST 树的节点都与一个 Token 实际位置相对应。
这颗树构造后,我们可以看到不同的类型是由对应的结构体来进行表示的。这里如果有语法、词法错误是不会被解析出来的。因为到目前为止说白了都是进行的字符串处理。
语义分析
编译器里边都把语法分析后的阶段叫做 语义分析,而go的这个阶段叫 类型检查;但是我看了以下go自己的文档,其实做的事情没有太大差别,我们还是按照主流规范来写这个过程。
那么语义分析(类型检查)究竟要做些什么呢?
AST 生成后,语义分析将使用它作为输入,并且的有一些相关的操作也会直接在这颗树上进行改写。
首先就是 Golang 文档中提到的会进行类型检查,还有类型推断,查看类型是否匹配,是否进行隐式转化(go没有隐式转化)。如下面的文字所说:
The AST is then type-checked. The first steps are name resolution and type inference, which determine which object belongs to which identifier, and what type each expression has. Type-checking includes certain extra checks, such as "declared and not used" as well as determining whether or not a function terminates.
大意是:生成AST之后是类型检查(也就是我们这里说的语义分析),第一步是进行名称检查和类型推断,签定每个对象所属的标识符,以及每个表达式具有什么类型。类型检查也还有一些其它的检查要做,像“声明未使用”以及确定函数是否中止。
Certain transformations are also done on the AST. Some nodes are refined based on type information, such as string additions being split from the arithmetic addition node type. Some other examples are dead code elimination, function call inlining, and escape analysis.
这一段是说:AST也会进行转换,有些节点根据类型信息进行精简,比如从算术加法节点类型中拆分出字符串加法。其它一些例子像dead code的消除,函数调用内联和逃逸分析。
上面两段文字来自 golang compile
这里多说一句,我们常常在debug代码的时候,需要禁止内联,其实就是操作的这个阶段。
# 编译的时候禁止内联 go build -gcflags '-N -l' -N 禁止编译优化 -l 禁止内联,禁止内联也可以一定程度上减小可执行程序大小
经过语义分析之后,就可以说明我们的代码结构、语法都是没有问题的。所以编译器前端主要就是解析出编译器后端可以处理的正确的AST结构。
接下来我们看看编译器后端又有哪些事情要做。
机器只能够理解二进制并运行,所以编译器后端的任务简单来说就是怎么把AST翻译成机器码。
中间码生成
既然已经拿到AST,机器运行需要的又是二进制。为什么不直接翻译成二进制呢?其实到目前为止从技术上来说已经完全没有问题了。
但是,
我们有各种各样的操作系统,有不同的CPU类型,每一种的位数可能不同;寄存器能够使用的指令也不同,像是复杂指令集与精简指令集等;在进行各个平台的兼容之前,我们还需要替换一些底层函数,比如我们使用make来初始化slice,此时会根据传入的类型替换为:makeslice64 或者 makeslice。当然还有像painc、channel等等函数的替换也会在中间码生成过程中进行替换。这一部分的替换操作可以在这里查看
中间码存在的另外一个价值是提升后端编译的重用,比如我们定义好了一套中间码应该是长什么样子,那么后端机器码生成就是相对固定的。每一种语言只需要完成自己的编译器前端工作即可。这也是大家可以看到现在开发一门新语言速度比较快的原因。编译是绝大部分都可以重复使用的。
而且为了接下来的优化工作,中间代码存在具有非凡的意义。因为有那么多的平台,如果有中间码我们可以把一些共性的优化都放到这里。
中间码也是有多种格式的,像 Golang 使用的就是SSA特性的中间码(IR),这种形式的中间码,最重要的一个特性就是最在使用变量之前总是定义变量,并且每个变量只分配一次。
代码优化
在go的编译文档中,我并没找到独立的一步进行代码的优化。不过根据我们上面的分析,可以看到其实代码优化过程遍布编译器的每一个阶段。大家都会力所能及的做些事情。
通常我们除了用高效代码替换低效的之外,还有如下的一些处理:
- 并行性,充分利用现在多核计算机的特性 流水线,cpu有时候在处理a指令的时候,还能同时处理b指令 指令的选择,为了让cpu完成某些操作,需要使用指令,但是不同的指令效率有非常大的差别,这里会进行指令优化 利用寄存器与高速缓存,我们都知道cpu从寄存器取是最快的,从高速缓存取次之。这里会进行充分的利用
机器码生成
经过优化后的中间代码,首先会在这个阶段被转化为汇编代码(Plan9),而汇编语言仅仅是机器码的文本表示,机器还不能真的去执行它。所以这个阶段会调用汇编器,汇编器会根据我们在执行编译时设置的架构,调用对应代码来生成目标机器码。
这里比有意思的是,Golang 总说自己的汇编器是跨平台的。其实他也是写了多分代码来翻译最终的机器码。因为在入口的时候他会根据我们所设置的 GOARCH=xxx 参数来进行初始化处理,然后最终调用对应架构编写的特定方法来生成机器码。这种上层逻辑一致,底层逻辑不一致的处理方式非常通用,非常值得我们学习。我们简单来一下这个处理。
首先看入口函数 cmd/compile/main.go:main()
var archInits = map[string]func(*gc.Arch){ "386": x86.Init, "amd64": amd64.Init, "amd64p32": amd64.Init, "arm": arm.Init, "arm64": arm64.Init, "mips": mips.Init, "mipsle": mips.Init, "mips64": mips64.Init, "mips64le": mips64.Init, "ppc64": ppc64.Init, "ppc64le": ppc64.Init, "s390x": s390x.Init, "wasm": wasm.Init, } func main() { // 从上面的map根据参数选择对应架构的处理 archInit, ok := archInits[objabi.GOARCH] if !ok { ...... } // 把对应cpu架构的对应传到内部去 gc.Main(archInit) }
然后在 cmd/internal/obj/plist.go 中调用对应架构的方法进行处理
func Flushplist(ctxt *Link, plist *Plist, newprog ProgAlloc, myimportpath string) { ... ... for _, s := range text { mkfwd(s) linkpatch(ctxt, s, newprog) // 对应架构的方法进行自己的机器码翻译 ctxt.Arch.Preprocess(ctxt, s, newprog) ctxt.Arch.Assemble(ctxt, s, newprog) linkpcln(ctxt, s) ctxt.populateDWARF(plist.Curfn, s, myimportpath) } }
整个过程下来,可以看到编译器后端有很多工作需要做的,你需要对某一个指令集、cpu的架构了解,才能正确的进行翻译机器码。同时不能仅仅是正确,一个语言的效率是高还是低,也在很大程度上取决于编译器后端的优化。特别是即将进入AI时代,越来越多的芯片厂商诞生,我估计以后对这方面人才的需求会变得越来越旺盛。
总结
总结一下学习编译器这部分古老知识带给我的几个收获:
知道整个编译由几个阶段构成,每个阶段做什么事情;但是更深入的每个阶段实现的一些细节还不知道,也不打算知道; 就算是编译器这种复杂,很底层的东西也是可以通过分解,让每一个阶段独立变得简单、可复用,这对我在做应用开发有一些意义; 分层是为了划分指责,但是某些事情还需要全局的去做,比如优化,其实每一个阶段都会去做;对于我们设计系统也是有一定参考意义的; 了解到 Golang 对外暴露的很多方法其实是语法糖(如:make、painc etc.),编译器会帮我忙进行翻译,最开始我以为是go代码层面在运行时去做的,类似工厂模式,现在回头来看自己真是太天真了;
5. 对接下来准备学习Go的运行机制、以及Plan9汇编进行了一些基础准备。
极牛网精选文章《走进Golang之编译器原理》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/6248.html
 微信公众号
微信公众号  微信小程序
微信小程序