干货概览
作为一个合格的码农,我们每时每刻都在为开发新功能、修复Bug、提升系统性能挥洒汗水。变更发布是产品迭代的必经之路,但是变化总伴随着风险,互联网公司轰动一时发生的大故障,往往跟变更有关。一半以上的故障是由变更引入的,毫无疑问,减少变更引入的故障能够显著提升服务的稳定性。
减少变更引入故障的基本方法是规范开发流程、提升开发质量、加强QA测试环节,从而避免将有问题的版本发布到线上,防患于未然。但是,由于线上环境与测试环境往往存在差异,一些变更在测试环境中工作正常,但是在线上环境会暴露出故障。这些变更成为了薛定谔的猫,只有在上线后才能揭晓是否存在故障。
因此,在发布过程中对服务健康情况进行跟踪检查、及早发现变更引入的故障成为发布过程不可或缺的环节,这样才能避免系统卷入重大故障的血案中。本文将介绍百度是如何对变更发布进行分级、检查来控制变更故障影响范围的。
分级发布,让故障影响范围可控
在百度,我们采用分级发布机制来发布变更到线上环境。分级发布将变更发布过程拆分成多个阶段,每个阶段只将变更应用到部分机器上,并在相邻的两个阶段之间对服务的健康情况进行检查。如果发现服务的健康度显著下降,则可以中止甚至回滚变更。在这个过程当中,大部分故障都能够在最后一个阶段之前被发现,因此故障通常只影响已经应用了变更的部分机器,从而有效地控制了故障的影响范围。
分级发布拆分的阶段越多,越能够在变更全面应用之前发现问题。但是,阶段的数量也并非越多越好,因为每个阶段都需要花费一定的时间来应用变更和检查健康度,阶段的数量大必然导致发布的时间变长,从而降低发布的效率。图1给出了百度内部分级发布的最佳实践方案。
方案包含5个阶段,依次为沙盒环境、单机房少量机器、单机房全量机器、其他所有机房少量机器、以及其他所有机房全量机器。这种划分方法平衡了故障风险和变更发布效率,在每个阶段制定了对应的故障止损预案,在实践中取得了很好的效果。
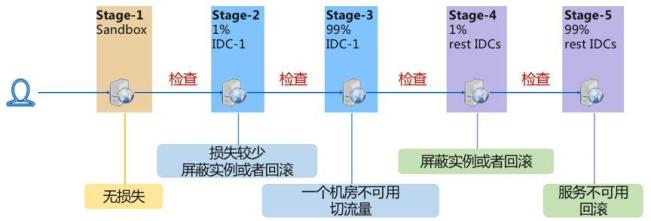
将变更发布过程拆分成多个阶段是基础,相邻的两个阶段之间服务健康度检查是核心。如果在各阶段发布后未进行服务健康度检查或者检查方法无效,即使将变更发布划分成了多个阶段,故障最终将扩展到所有机器。
因此,分级发布检查是否有效直接决定了故障引发的损失量。下面将重点介绍如何进行分级发布检查。
更快、更准发现变更潜在隐患
1. 人工检查,变更发布效率无法保证
人工检查是最容易想到的检查方法,当一个阶段变更发布结束后,运维工程师会去监控平台对核心指标的波动情况进行逐一检查。如发现有波动异常的指标,则认为本次变更存在问题,中止甚至回滚变更。
在百度,运维工程师会检查CPU等系统指标以及请求量等业务指标,需要检查的核心指标个数一般在300个以上。为了保证变更发布效率,一次变更发布除去机器重启的时间,留给人工检查的时间通常只有10分钟左右。根据上述的分级发布流程,一共存在4个检查点,这就意味着要保证变更发布效率,运维工程师需要在0.5(10*60/4/300)秒内完成一个指标的检查。
我们知道,在对指标检查的时候,不单要看当前的波动,还要参考指标在历史上的波动情况,0.5秒完成一个指标的检查人工是无法做到的。
2. 基于人工规则检查,阈值选择、更新是难题
每次变更发布后人工检查核心指标耗时耗力,能否将人工检查的经验转化成规则,变更发布时基于规则进行自动检查?这就是基于人工规则自动检查。首先,人工根据指标的波动情况,给指标设定不同的阈值。当服务变更发布后,会自动启动服务健康状态检查脚本,脚本会将当时的指标采集值与人工设置的阈值进行比较,若存在指标采集值未落入人工配置的阈值范围内,则判断本次变更可能引入了故障,中止变更并通知运维同学进行处理。
如图2所示的两个指标,人工给请求量指标设置的阈值上界为2.2k、下界为1.5k;对于请求失败数指标,用户只关心指标上涨,因此给指标设置了20的上界。变更发布后,请求量指标在1.5k ~ 2.2k之间波动,判断该指标正常;请求错误数超过了人工配置的上界20,判断该指标异常,需要中止变更。
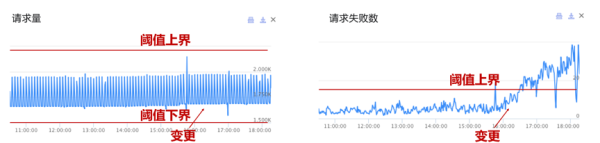
基于人工规则检查将检查过程自动化,大幅提升了变更发布效率的同时也节省了人力成本。但是人工规则检查面临两大难题:阈值选择、阈值更新。
首先,应该设置什么样的阈值是一个很难回答的问题,图3(a)为某服务的错误日志数指标,人工根据经验将阈值上界设为15,在一次变更发布后错误数发生了明显的上涨,但未达到人工设置的阈值,因此基于人工规则无法发现这次变更引入的故障,导致故障扩散到所有机房,影响了服务的稳定性。
另外,人工配置阈值也并非一劳永逸,当指标水位发生变化后,需要对阈值进行更新。如图(b)是某服务的请求量指标,历史请求量经常维持在1.3k,人工将阈值设置在1.2 ~ 1.4k。随着业务的发展,服务的请求量有了突增达到了1.6k,需要人工对阈值进行调整。

3. 智能检查,安心躺着做变更
鉴于人工规则检查存在阈值选择、更新困难的问题,迫切需要有更智能的检查方法。我们对一些引入故障的变更进行分析发现,大部分的故障会导致指标突变,运维工程师往往对发生突变的指标格外关注。同时,我们也发现,在变更场景下,指标突变不一定代表变更引入了故障。
比如,当在流量上涨期间进行变更发布时,流量相关的指标必然会发生突增。再比如,在变更发布过程中伴随着进程重启,像内存、文件句柄等指标可能会因为资源释放而发生突降。因此,智能检查算法由两部分组成:度量指标是否发生突变、对突变是否合理进行判断。若指标在变更发布前后发生了无法解释的突变,则认为指标异常。
指标突变是否合理可以从以下两个角度进行解释:突变是否由时间因素、重启导致。由于时间因素的影响会同时施加在应用变更的机器(实验组)和未应用变更的机器(对照组),可以根据对照组来排除时间因素的影响;进程重启对指标的影响可以通过历史变更来建模。当对照组与历史变更均无法解释指标突变时,则认为指标异常,需要中止变更。智能检查无需人工配置参数,可以自动、智能地识别异常突变的指标。
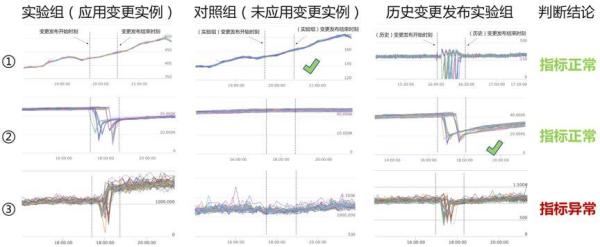
图4给出了一个具体的例子,每一行代表一个指标,对于每个指标都展示了在某次变更发布前后的波动情况、对照组在对应时间的波动情况以及指标在历史一次正常的变更发布前后的波动情况。
对于指标①,指标在本次变更发布后出现了上涨,但是对照组也出现了类似程度的上涨,因此判断上涨是由时间因素导致,指标变化正常;对于指标②,变更发布后指标出现突降,历史正常变更发布后指标都会发生突降,因此判断突降是由进程重启导致的,指标变化正常;对于指标③,变更发布后发生了突增,而对照组跟历史变更发布后均未发生明显变化,即指标突变无法被对照组、历史变更解释,指标异常,需要中止甚至回滚变更。
总结
以上就是我们使变更发布更加安全高效的方法,智能检查算法是减少故障损失的核心。算法基于历史变更和对照组进行,不需要人工配置参数,具有普适性。希望能够对大家有所帮助,如有任何想法和疑问,欢迎一起交流。
极牛网精选文章《被变更逼疯的码农,是如何成功自救的?》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/6667.html
 微信公众号
微信公众号  微信小程序
微信小程序