与计算机视觉相比,自然语言处理一直被认为是一个难以解决的问题。本文找到了一种新的自然语言处理方法,探索了自然语言处理和计算机视觉处理的结合,将文本画成图片。虽然目前的精度尚未优化,但看起来很有希望。
问题点
自然语言处理长期以来被认为是一个难以解决的问题,至少与计算机视觉相比是如此。NLP模型需要更长的运行时间,通常更难实现,并且需要更多的计算资源。另一方面,图像识别模型的实现变得更简单,并且对GPU的负担更小。这提醒了我,我们能把文本语料库转换成图像吗?我们能把文本翻译成图像吗?事实证明答案是肯定的,并带来了令人惊讶的结果!我们用这种方法来区分虚假新闻和真实新闻。
在本文中,我们将详细讨论这种方法、结果、结论和以下改进。
简 介
思路来源
将文本转换成图像的想法最初是受Gleb Esman关于欺诈检测的文章启发的。在这种方法中,他们将各种数据点,例如鼠标移动的速度、方向和加速度,转换成彩色图像。然后在这些图像上运行一个图像识别模型,这可以产生非常精确的结果。
数据
所有实验中使用的数据都是乔治·麦金太尔虚假新闻数据集的子集。它包含大约1,000篇假的和真的新闻文章: https://github.com/cabhijith/fax-news/blob/master/fax或真的新闻。让我们先从更高的层面讨论文本2图像。基本想法是将文本转换成我们可以绘制的热图。热图识别每个单词的TF-IDF值。词频-逆文档频率(TF-IDF)是一种统计方法,用于确定一个单词相对于文档中其他单词的重要性。在对TF-IDF值进行基本预处理和计算之后,我们使用一些平滑高斯滤波器将它们绘制成对数尺度的热图。一旦绘制了热图,我们使用fast.ai实现了有线电视新闻网,并试图区分真实热图和虚假热图。我们最终达到了71%左右的稳定准确率,这是这种新方法的良好开端。这是一个关于我们方法的小流程图。还不清楚吗?
Text2Image 的基本原理
data为小写,所有特殊字符都被删除,文本和标题被连接。文档中超过85%的文本也被删除。此外,应该明确避免使用停止词。使用了一个标准的停顿词列表,大部分是没有信息的重复词。特别是,有必要修改假新闻的句子。这是一个值得未来探索的领域,尤其是它能给假新闻带来独特的写作风格。
预处理
Text2图像由tf-idf的scikit-learn实现,以便对关键词进行评分和提取。IDF分别计算虚假新闻语料库和真实新闻语料库。与整个语料库的单个IDF分数相比,计算单个IDF分数将导致准确性的显著提高。然后迭代计算每个文档的tf-idf分数。这里,标题和文本不是分开评分,而是一起评分。
Text2Image 详述
计算 TF-IDF
计算术语频率
处理 TF-IDF 值
计算IDF
将它们相乘得到tf-idf。我们分别迭代每个文档。
最终的热图
121个具有最高TF-IDF值的单词将被提取用于每个文档。这些字然后被用来创建一个11×11阵列。这里,选择的字数就像一个超级参数。对于更短和更简单的文本,可以使用更少的单词,可以使用更多的单词来表示更长和更复杂的文本。根据经验,11×11是该数据集的理想大小。TF-IDF值按大小降序排列,而不是按它们在文本中的位置进行映射。TF-IDF值以这种方式映射,因为它看起来更能代表文本,并且为模型提供了更丰富的训练特性。因为一个单词可以在一篇文章中出现多次,所以考虑一下第一次出现的单词。
不是按原样绘制TF-IDF值,而是按对数刻度绘制所有值。这样做是为了减少上下值之间的巨大差异。

训练我们的模型
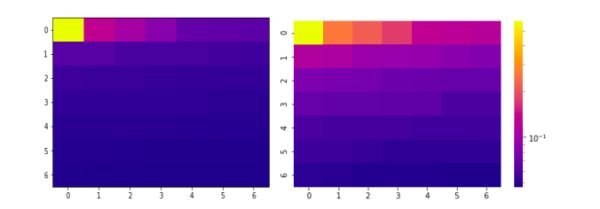
图1(左)显示了按原样绘制的TF-IDF值。图2(右)示出了对数标度上绘制的相同值
的缺点之一是在训练模型时大量过度拟合。这可以归因于缺乏任何数据扩展。目前,这个用例似乎没有可用的数据扩展方法。因此,高斯滤波用于平滑整个数据集上的这些映射。虽然它确实降低了一点准确性,但过度拟合的情况却显著减少了,尤其是在训练的初始阶段。
结果
最终热图尺寸为11×11,用海牛绘制。因为在训练期间,X轴、Y轴和颜色条没有传达任何信息,所以我们删除了它们。使用的热图类型是“等离子体”,因为它显示了理想的颜色变化。尝试不同的颜色组合可能是未来的一个探索领域。下面是最终情节的一个例子。
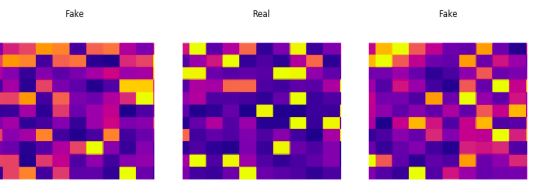
热图最终表格
该型号使用fast.ai在resnet34上进行训练。鉴定出489篇假新闻文章和511篇真新闻文章。在不增加数据的情况下,在训练集和测试集之间采用标准的80336020分段。所有用过的代码都可以在: https://github.com/cabhijith/Text2Image/blob/master/Code.html
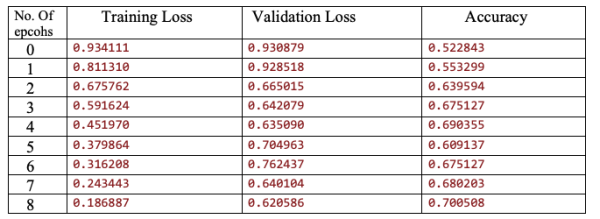
找到,经过9轮迭代,模型的精度达到70%以上。虽然这个数据集远非先进,但这种新方法似乎有很大的前景。以下是在培训过程中观察到的一些情况。
这个型号更糟糕。增加数据对过度拟合没有影响,这与我们的预期相反。进一步培训或改变学习率没有任何效果。
增大绘图尺寸有助于提高精度,直到尺寸达到11×11,然后增大绘图尺寸会导致精度下降。
在地图上使用一定量的高斯滤波有助于提高精确度。
目前,我们正在研究词性标注和手套单词嵌入的可视化。我们也在考虑修改停止字和改变绘图的大小和颜色模式。我们将继续改进!
极牛网精选文章《Text2Image:一种新的NLP思路》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/2063.html
 微信公众号
微信公众号  微信小程序
微信小程序 







