在AI技术爆发式迭代的当下,我们以多模态混合智能架构为核心,融合深度学习、知识图谱与边缘计算,打造了可无缝嵌入业务核心业务的AI中枢系统。DeepSeek大模型的开源推动了AI大模型想产业私有化部署产业化应用的发展,让一线能力的国产大模型走进企业,为千行百业赋能。
本文中蓝典信安AI实验室记录一次DeepSeek R1 671B满血版部署过程,手把手教您如何部署并调用本地化大模型。算力服务器搭载8卡H200 SXM5 141GB显存,最大可达1128GB的VRAM,足以承载FP8精度的DeepSeek-R1满血版进行推理使用。

基础操作系统准备
首先进行一些基础环境的准备工作,包括服务器操作系统的选择,相关驱动的安装,模型的下载等等。
环境部署中,系统版本选择Ubuntu24.04 LTS作为服务器操作系统,采用UEFI的模式进行系统引导,同时对磁盘进行相应的分区,其中/boot/efi分区分配1GB,/boot分区分配1GB,/分区分配剩余所有的磁盘空间。
NVIDIA驱动的安装+CUDA+cuDNN
安装驱动前需要进行几步环境配置操作:
步骤一、安装gcc、g++、make、cmake等依赖包
# apt-get install gcc g++ make cmake -y
步骤二、禁用默认开源驱动nouveau
在终端内输入:
# nano /etc/modeprobe.d/blacklist.conf
在弹出的文本末尾加上两句后进行保存:
blacklist nouveau
options nouveau modeset=0
在终端内输入以下命令更新文件:
# sudo update-initramfs -u
确认上述操作已完成,并重启服务器后,在终端内输入:
# lsmod | grep nouveau

没有输出就说明禁用nouveau成功了。
NV驱动安装:
Nvidia的驱动下载需要前往NVIDIA的官网进行,本次安装将采用最新驱动570.124.06进行使用,官网链接:https://www.nvidia.cn/drivers/lookup/

下载后的驱动文件为.run后缀结构,以目前下载的驱动为例,导入服务器后需要给该驱动赋予执行权限。
# chmod +x NVIDIA-Linux-x86_64-570.124.06.run
输入下列命令开始安装:
# sudo ./NVIDIA-Linux-x86_64-570.124.06.run -no-opengl-files -no-x-check
相关参数说明:
-no-opengl-files :不安装 opengl库(据说该库不好用)。
-no-x-check:安装驱动时关闭X服务。
出现第一个选项选择continue installation
第二个选项是否安装32-bit包,选择:No
第三个选项 automatically update X configuration 选择:Yes
完成安装。
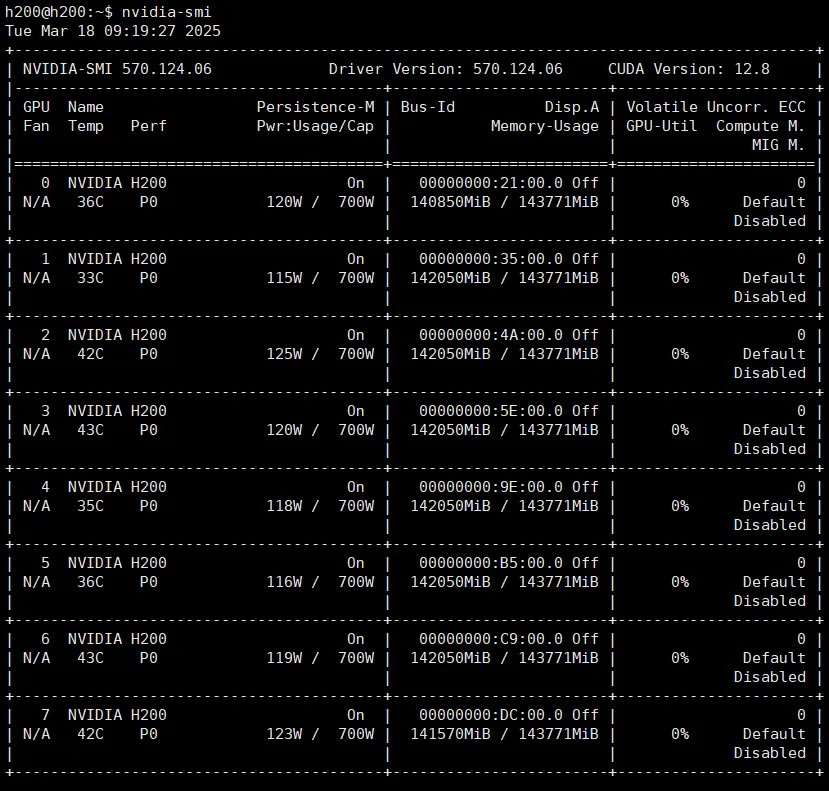
此时,已经完成NVIDIA驱动的安装。在终端内输入:
# nvidia-smi
CUDA安装:
CUDA安装将采用NVIDIA官网的模式进行,选择的CUDA版本为12.8,官网链接为:
https://developer.nvidia.com/cuda-12-8-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=24.04&target_type=deb_local

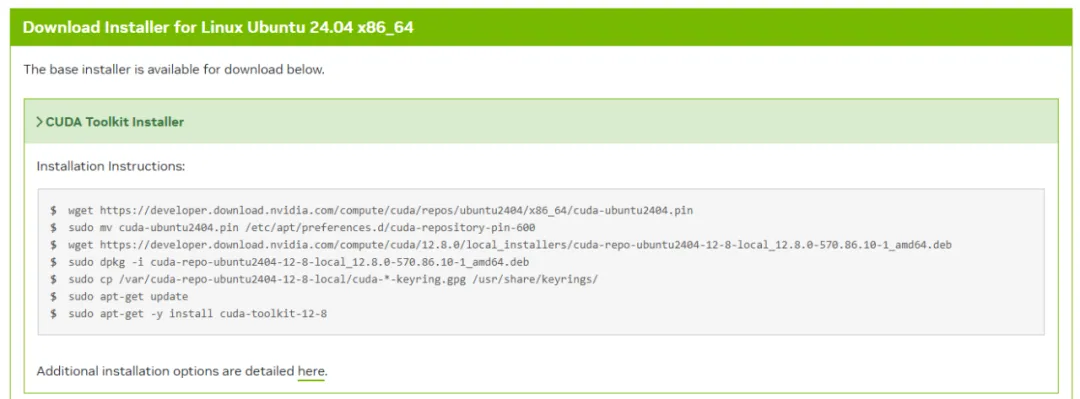
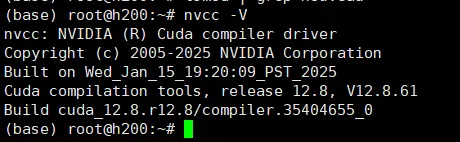
参照官网给出的指令顺序安装,安装结束后可以在终端执行:
# nvcc -V
查看输出的版本信息:
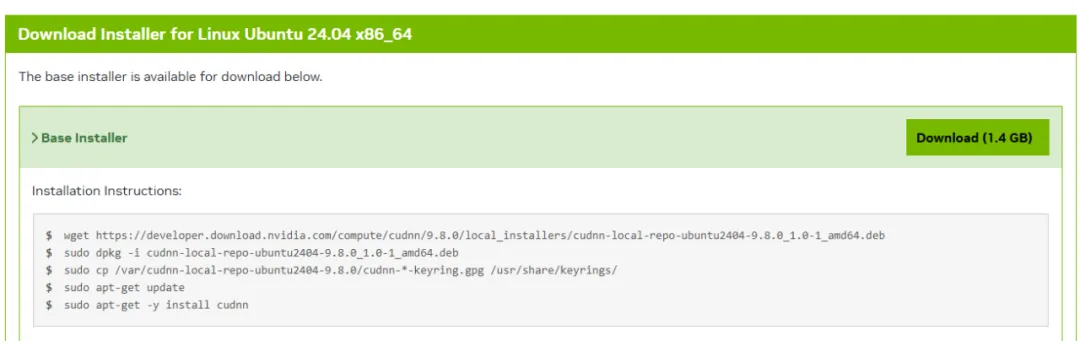
cuDNN安装:
cuDNN采用与cuda相同的安装方式,选择的版本为9.8.0,官网链接为:
https://developer.nvidia.com/cudnn-downloads?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=24.04&target_type=deb_local
着重点:
H200 SXM5采用NVLink的方式进行连接,需要安装NVLink/NVSwitch工具集来保证显卡的正常调用,否则启动模型时会出现以下报错:
CUDA initialization: Unexpected error from cudaGetDeviceCount()
解决方案:
检查是否安装 nvidia-fabricmanager:
# dpkg -l | grep nvidia-fabricmanager
未安装执行:
# version=570.124.06
# main_version=$(echo $version | awk -F ‘.’ ‘{print $1}’)
# apt-get update
# apt-get install -y nvidia-fabricmanager-${main_version}=${version}-*
启动服务:
# systemctl enable nvidia-fabricmanager
# systemctl start nvidia-fabricmanager
vLLM环境部署+模型启动:
部署环境基于conda进行隔离,需要提前安装miniconda3并创建环境:
# curl -O https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh | bash
模型下载:
在创建的环境内安装对应huggingface-pip包:
# pip install huggingface-hub
国内可采用镜像加速:
# export HF_ENDPOINT=https://hf-mirror.com
通过huggingface-cli工具进行模型下载(其中V3:671B完整版大小为642GB,R1:671B完整版大小为662GB):
# huggingface-cli download –resume-download {huggingface模型名称,例如deepseek-ai/DeepSeek-R1} –local-dir {模型存放目录}
基于conda环境部署的vllm:
创建conda环境:
# conda create -n vllm
# conda activate vllm
安装python,建议使用如果cuda版本处于12.6及以上,建议使用Python3.10及以上:
# conda install python=3.11
通过pip指令安装vllm:
# pip install vllm
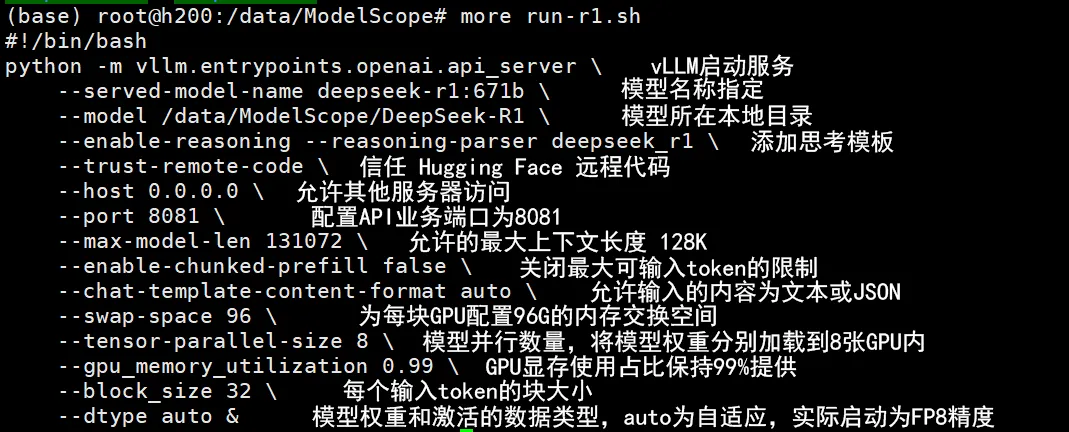
启动vllm脚本示例:
特别说明
1、enforce-eager参数
网络上对于–enforce-eager参数的说法五花八门,该功能的解释是用于控制vLLM是否始终使用PyTorch的eager模式(即时执行模式),默认为False,vLLM会默认使用eager模式和CUDA图的混合模式来执行操作,这种混合模式旨在提供最大的性能和灵活性。
网络多数讲解建议开启该功能切换到True,实测8*H200部署DeepSeek-R1:671B满血版应保持该参数为False,确保CUDA能用于模型的加速调用。
2、输入最大tokens保障
–enable-chunked-prefill false 参数需要填入,未填入默认只有2048token 无法满足长文本的输入,会造成无回复的情况发生,但过长文本会造成爆显存,模型中断服务的情况。
–max-num-batched-tokens 可以调整enable-chunked-prefill中提到的2048 token限制,根据显卡的实际情况,对最大输入token进行相应的配置调整。
3、内存调用作为缓存使用
–swap-space 该参数为调用部分内存为GPU的缓存空间,默认单位为GB,请根据实际情况进行相应配置和填写。
· 蓝典信安AI实验室,构建体系化AI安全能力
深圳市蓝典信安科技有限公司 (简称: 蓝典信安®),隶属于蓝典科技股份有限公司 (股票代码872739),是一家深耕于网络空间安全领域,拥有自主研发能力及核心知识产权,提供网络安全解决方案与技术服务的高新科技企业。
蓝典信安®以「AI驱动网络空间安全治理」为使命,围绕下一代网络安全攻防技术体系,致力于构建人工智能安全、云计算安全、大数据安全等新一代IT基础设施安全能力,持续探索「安全AI」和「AI安全」的技术发展和合规建设。
蓝典信安AI实验室,依托蓝典二十年持续的信息安全技术积累,在人工智能安全方向扎根研究,在AI应用的全新技术背景下,构建出体系化的AI安全能力和产品,为AI赋能千行百业提供坚实的安全保障。

极牛网精选文章《蓝典信安AI实验室基于H200的DeepSeek-R1满血版部署:技术细节与优化指南》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/28024.html
 微信公众号
微信公众号  微信小程序
微信小程序 







