
作者简介:叶绍琛,网络安全专家,公安部全国网络警察培训基地特聘专家,网络安全110智库专家,NgSecGPT开源网络安全大模型核心开发者,中国下一代网络安全联盟AI安全专委会理事,CTFWAR国际网络安全攻防对抗联赛裁判长,网络安全期刊《网安观察》总顾问,曾获国家科技部和教育部联合颁发的教育信息化发明创新奖。
当开源第三方库成为移动应用的血肉,一行缺陷即可瞬间扩散到千万台设备;传统模糊测试和人工打补丁的节奏,已追不上漏洞被利用的速度。大模型的出现,让“测试-修复”第一次有机会在同一台 GPU 上并行完成。
本文聚焦两项最新实践:用 FuzzGPT 把大模型变成“无限QA工程师”,以及用 RepairLLaMA 让大模型化身“7×24随叫随到的程序员”。它们共同指向一个拐点——AI 不只是发现风险,还将直接消灭风险。
一、通过大模型进行模糊测试
随着应用程序功能的模块化与复杂化,大量软件开发者倾向将针对某种功能的代码封装成第三方库,应用程序开发者只需要引入第三方库,即可快速优雅地解决对应的问题,但这也导致了某些比较知名的第三方库被大量的应用所依赖,因此代码库的质量至关重要。为了保障代码的质量,Fuzzing技术近年来被用来在软件开发的测试阶段检测代码中是否存在Bug。
Fuzzing是一种强大的Bug发现方法,通过随机生成输入来进行测试程序代码在各种开发者意料之外的情景下的表现。传统的Fuzzing技术在处理一个全新的代码库之前,需要依赖人工来构建测试用例的生成与变异的策略。因此,有研究者提出,可以利用大模型对语言的理解与处理能力,由大模型阅读代码库,再批量生成测试用例。
来自美国伊利诺伊大学厄巴纳-香槟分校的研究者提出了一种引导大模型生成测试输入程序的技术,称为FuzzGPT。FuzzGPT 针对的是python的深度学习的代码库,研究者们通过爬虫程序,从目标库GitHub页面的问题跟踪系统中收集所有的问题和拉取请求,从其中的错误报告中筛选出包含重现Bug的代码块,对这些代码块执行自动化注释操作。
由于数据集中的每个代码片段通常涉及多个API,因此无法直接提取确切的错误API,研究者们通过为大语言模型提供少量示例提示,大语言模型通过上下文学习,理解注释操作的目的后,由模型对数据集中的错误代码完成注释。
数据集准备完毕后,研究者采用了三种不同的学习策略,分别是少样本、零样本和微调:
1. 少样本学习(Few-shot learning):
少样本学习策略的提示词结构如图1所示,少样本学习策略中的样本包括API名称、从GitHub错误报告页面中获得的错误描述,以及最终的错误触发代码片段。样本的目的有两个:引导大语言模型生成所需的输出格式、使模型能够通过观察历史错误触发代码片段来学习产生类似的边缘情况代码片段,而无需修改模型参数。
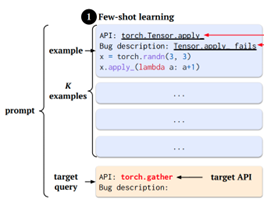
图1 少样本学习策略的提示词结构
2. 零样本学习(Zero-shot learning):
零样本学习策略不会给大模型提供完整的样本以及代码片段,而是通过插入了代码片段的提示词让大语言模型直接生成测试代码片段。零样本学习策略的提示词结构如图2所示,零样本学习策略包含两种变体:
2.1. 零样本补全:
这种变体中,提示词的模板是: `# The following code reveals a bug in {target_api}` 其中target_api部分会被替换成数据集中随机的代码片段,并且随机去除掉代码片段的后缀,只提供代码片段的少量前缀。当提示词提交给大语言模型后,模型会将代码片段进行补全,形成一个新的测试代码片段。
2.2. 零样本编辑:
这种变体的所使用的提示词模板是:`# Edit the code to use {target_api}` 与零样本补全不同,target_api部分会被替换为完整的错误代码,当提示词提交给大语言模型后,模型会以target_api部分代码为模板,生成新的测试代码片段。

图2 零样本学习策略的提示词结构
3. 微调:
少样本学习与零样本学习,本质上是通过提示词,利用模型的上下文学习能力影响模型的输出,模型自身的参数不会被改变,因此每次调用模型,就必须要给模型发送提前设计好的提示词。微调则是使用数据集对大语言模型进行训练,调整模型内部的参数,使模型学习到数据集中的内容,减少模型在生成测试代码过程中对上下文的依赖,提高生成测试代码的准确性。
表1为采用三种策略的FuzzGPT对PyTorch与TensorFlow代码库进行模糊测试的表现,表中列#APIs、#Prog.和Cov展示了API数量、独特程序和行覆盖的情况。Valid表示只考虑没有运行错误的程序,All表示考虑了所有生成的独特程序。Valid(%)计算了所有生成的独特程序中有效程序的比例。
从表1中可以观察到,FuzzGPT-FS在测试中具有最多的被覆盖API和独特(有效)程序。原因是少样本学习策略在提示词中为大模型提供了丰富的上下文,使大模型能够学习与组合各种错误案例,使用多样化的API,FuzzGPT-ZS的有效率比其它策略低,零样本学习策略的提示词中携带的信息相对较少,并且大模型需要生成与提示词中提供的代码兼容的新代码,因此模型可参考的信息以及发挥的空间相对比较有限。
FuzzGPT-FT在两个代码库上的表现都比较可观,并且在针对PyTorch库的测试中拥有最高的覆盖率。微调过的模型通过更新模型内部参数的方式学习了训练集中的所有错误案例,并且在每一次推理中会选择并组合所学的信息,而少样本学习受限于提示词长度,上下文提供的案例有限。但是微调策略需要收集高质量的微调数据集,并且需要为每个不同的任务训练不同的大模型,在计算资源和存储方面的成本比其它两种策略更高。
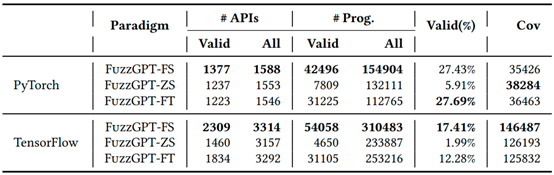
表1 采用三种策略的FuzzGPT进行模糊测试的表现
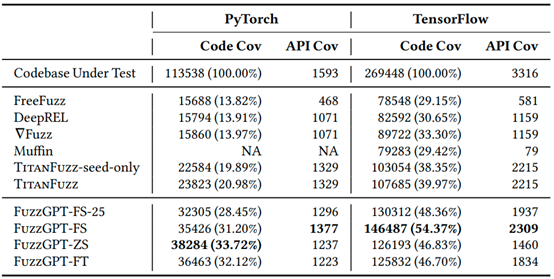
表2 FuzzGPT 与现有Fuzzer工具的对比
表2是三种FuzzGPT变体与现有的Fuzzer工具对PyTorch和TensorFlow代码库的测试结果,表格数据表明,三种FuzzGPT变体在代码覆盖率方面显著优于现有的Fuzzer工具,表现最好的
根据实验结果,三种FuzzGPT变体在代码覆盖率方面显著优于所有现有fuzzer,包括最先进的TitanFuzz。FuzzGPT-FS 在 TensorFlow代码库中实现了54.37%的行覆盖率,比TitanFuzz提高了36.03%。FuzzGPT-ZS在PyTorch代码库上实现了33.72%的行覆盖率,比TitanFuzz提高了60.70%。这显示了大模型在Fuzzing方面的优越性。
虽然研究所使用的数据是Python语言编写的深度学习代码库,但是大语言模型的文本处理能力具有很强的通用性,也可以被用在Java语言、C#语言等移动应用常用的软件库中。
二、利用大模型自动化修复错误代码
自动化程序修复(APR)旨在无需人工干预的情况下自动修复软件缺陷。基于深度学习的修复方法已经成为自动化程序修复的主流方案,这归功于深度神经网络学习复杂缺陷修复模式的强大能力。而大模型的出现,将基于深度学习的修复推向了一个新的台阶。
来自瑞典皇家理工学院的A. Silva等研究者提出了RepairLLaMA,使用针对特定代码微调过的大语言模型来修复错误代码。RepairLLaMA采用了Low-Rank Adaption(LoRA)技术来微调模型。
Low-Rank Adaption(LoRA)技术的核心思想是在不改变原有模型参数权重的情况下,通过添加少量新参数来进行微调。LoRA会为原有模型引入一个少数参数组成的低秩矩阵,然后在微调大模型的过程中,只更新这个低秩矩阵的参数,保持原有模型参数不变,微调完成后,低秩矩阵被称为LoRA模型,其体积通常远小于原有的大模型,然后将LoRA模型与大模型一起加载到内存与显存中进行推理,从而使大模型在不改变自身已有知识的前提下,通过LoRA获取新的知识。同一个LoRA模型可以与不同的大模型进行配合,而大模型也可以切换使用不同的LoRA模型,比起全参数微调,LoRA微调技术显然效率更高,更加灵活。
RepairLLaMA使用开源的CodeLLaMA-7B模型作为LoRA微调的基座模型,CodeLLaMA模型是针对代码生成任务进行训练的的大模型,其训练集主要由大量代码构成,在代码生成的任务表现要优于GPT-3.5模型。
RepairLLaMA的微调数据集是在一个专注于 Java 语言的源代码差异(diffs)的Megadiff数据集的基础上修改而来的,包含了从开源项目中提取的663,029 个 Java 源代码差异(diffs),微调数据集将Megadiff数据集中筛选出 30,000 到 50,000 对微调样本。
RepairLLaMA 将针对Java代码中缺陷生成补丁代码,研究者在设计微调过程中所选用的缺陷特点包括:
1. 功能性缺陷,并且至少有一个失败的测试用例。
2. 可以通过更改单个函数来修复的缺陷。
3. 支持需要在函数的多个位置进行更改的缺陷。
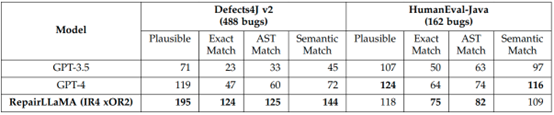
表3 RepairLLaMA与基于ChatGPT的APR技术的修复效果比较
表3的内容是RepairLLaMA与基于ChatGPT的APR技术的修复效果比较,实验选取了Defects4J和HumanEval-Java 两个Java基准测试,其中Defects4J包含来自17个开源Java项目的共488个单函数缺陷,HumanEval-Java包含162个单函数缺陷。大模型生成的补丁通过以下四个指标进行评价:
1. Plausible:合理的补丁,即成功通过所有测试用例的补丁。
2. Exact Match:完全匹配的补丁,在文本上与开发者提供的参考补丁完全相同,包括格式。
3. AST Match:语法树匹配补丁,具有与开发者提供的参考补丁相同的抽象语法树(Abstract Syntax Tree, AST)。
4. Semantic Match:语义匹配补丁,经过专家评估后被认为是等效的补丁。
由表3的内容可知,RepairLLaMA 在测试数据上的表现明显优于商用的大模型GPT-4以及GPT-3.5。
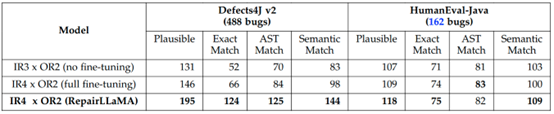
表4 RepairLLaMA与全参数微调、无微调模型之间的对比
表4展示了使用LoRA微调的RepairLLaMA与使用全参数微调、无微调模型之间在测试数据上表现的对比,RepairLLaMA在多数项目中的表现要优于全参数微调以及无微调模型。总体来说,RepairLLaMA 所使用的LoRA微调技术相比全参数微调而言,所需要的资源更少,且由于微调所使用的数据量远少于全量训练所使用的数据量,使用全参数微调的模型容易出现过拟合的情况,从而影响模型的表现。LoRA技术仅会影响大模型的一部分参数,可以有效地避免过拟合,提高大模型的表现。
三、总结
从 FuzzGPT 的覆盖率跃升到 RepairLLaMA 的高精度补丁,我们看到大模型已能贯穿“找缺陷→补缺陷”的完整闭环。下一步的挑战,是如何把这两条流水线嵌入 CI/CD,让每一次代码递交都在秒级完成 AI 驱动的安全体检与修复。
当 AI 开始自我加固,攻防天平或将重新校准:攻击者需要对抗的不再是散落的人力,而是一座持续进化的“模型城墙”。把握这一窗口期,把大模型从实验台搬进生产线,将决定未来移动生态的安全基线。
本文来源自清华大学出版社《移动安全—逆向攻防实践》网络空间安全学科教材(ISBN:9787302690511)

极牛网精选文章《当大模型遇上移动安全:AI在移动安全测试与漏洞修复的应用》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/28312.html
 微信公众号
微信公众号  微信小程序
微信小程序 







