为什么数据处理很重要?
熟悉数据挖掘和机器学习的小型合作伙伴都知道,与数据处理相关的工作时间占整个项目的70%以上。数据的质量直接决定了模型的预测和泛化能力。它涉及许多因素,包括准确性、完整性、一致性、及时性、可信度和解释。

在真实数据中,我们得到的数据可能包含大量缺失值,可能包含大量噪声,或者可能由于人工输入错误而出现异常点,这对算法模型的训练非常不利。数据清理的结果是以相应的方式处理各种脏数据,以获得用于数据统计和数据挖掘的标准、干净和连续的数据。
有哪些数据预处理的方法?
数据预处理的主要步骤是:数据清理、数据集成、数据规范和数据转换。本文将从这四个方面详细介绍具体的方法。如果您在项目中做好这些方面的数据处理,将会对后续的建模有很大的帮助,并且可以很快取得良好的效果。
数据清理
data cleaning的主要思想是通过填充缺失值、平滑有噪声的数据、平滑或删除异常值以及解决数据不一致来“清理”数据。如果用户认为数据混乱,他们不太可能相信基于数据的挖掘结果,即输出结果不可靠。
1、缺失值的处理
在现实世界中,在获取信息和数据的过程中,有各种原因导致数据丢失和空缺。这些缺失值的处理方法主要基于变量的分布特征和变量的重要性(信息含量和预测能力),使用不同的方法。主要分为以下几种类型:
哑变量填充:如果变量是离散的,并且具有较少的不同值,则可以转换为哑变量,例如SEX sex变量,有三种不同的mal、fameal、na值,并且该列可以转换为:is _ sex _ mal、is _ sex _ female、is _ sex _ na。如果一个变量中有十几个不同的值,频率较小的值可以根据每个值的频率分为一个类别“其他”,从而减小了维数。这种方法最大化了关于保留变量的信息。
综上所述,房东常用的方法是:首先,熊猫. isnull.sum()用于检测变量的缺失比例,并考虑删除或填充。如果要填充的变量是连续的,一般使用平均值法和随机差值来填充。如果变量是离散的,通常使用中间变量或虚拟变量来填充。
注意:如果变量被划分成盒子并离散化,丢失的值通常被视为盒子(离散变量的值)
2、离群点处理
离群值是数据的正态分布,特定分布区域或范围之外的数据通常被定义为异常或噪声。异常可以分为两种类型:“伪异常”。由于特定的业务操作,它们通常反映业务状态,而不是数据本身。“真实异常”不是由特定的业务操作引起的,而是数据本身的异常分布,即异常值。检测异常值的方法主要有以下几种:
简单统计分析:根据箱线图和每个轨迹判断是否有异常。例如,熊猫的描述功能可以快速发现异常值。
3原则:如果数据呈正态分布,则偏离平均值的3。一般定义:范围内的点是异常值。
基于聚类:使用聚类算法丢弃远离其他聚类的小聚类。
总之,异常值被认为是影响数据处理阶段数据质量的异常值,而不是通常的异常检测目标点。因此,宿主通常采用相对简单直观的方法,结合boxmap和MAD统计方法来判断变量的异常值。
Specific processing methods:
根据异常点的数量和影响,考虑是否删除该记录。如果异常值在数据对数变换后被消除,则该方法在不损失信息的平均值或中值的情况下生效,以替换异常点。它简单高效,信息丢失少。在训练树模型时,树模型对异常值具有较高的鲁棒性,并且没有信息损失。模型训练效果不受影响
3、噪声处理
Noise是变量的随机误差和方差,是观测点和实点之间的误差,即
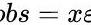
Common processing methods:将数据分成等频率或等宽度的盒子,然后用每个盒子的平均值、中值或边值(不同的数据分布、不同的处理方法)替换盒子中的所有数字,使数据平滑。另一种方法是建立变量和预测变量的回归模型,并根据回归系数和预测变量,反求自变量的近似值。
数据集成
数据分析任务主要涉及数据集成。数据集成将来自多个数据源的数据组合到一致的数据存储中,例如数据仓库。这些来源可能包括多个数据库、数据方或一般文件。
实体识别问题:例如,数据分析者或计算机如何才能确信一个数 据库中的 customer_id 和另一个数据库中的 cust_number 指的是同一实体?通常,数据库和数据仓库 有元数据——关于数据的数据。这种元数据可以帮助避免模式集成中的错误。 冗余问题。一个属性是冗余的,如果它能由另一个表“导出”;如年薪。属性或 维命名的不一致也可能导致数据集中的冗余。用相关性检测冗余:数值型变量可计算相关系数矩阵,标称型变量可计算卡方检验。 数据值的冲突和处理:不同数据源,在统一合并时,保持规范化,去重。
数据规约
数据简化技术可用于获得数据集的简化表示,数据集要小得多,但仍能保持原始数据的完整性。这样,对精简数据集的挖掘将更加有效,并产生相同(或几乎相同)的分析结果。通常有以下策略:
1、维度规约
用于数据分析的数据可能包含数百个属性,其中大多数属性与挖掘任务无关且冗余。维度缩减通过删除不相关的属性来减少数据量并确保最小的信息损失。
属性子集选择:目标是找到最小属性集,以便使用所有属性使数据类的概率分布尽可能接近原始分布。对压缩属性集进行挖掘还有其他优势。它减少了发模式中出现的属性数量,使模式更容易理解。
逐步向前选择:此过程从一个空属性集开始,选择原始属性集中的最佳属性,并将其添加到该属性集中。在随后的每次迭代中,原始属性集中剩余属性中的最佳属性被添加到该集合中。
逐步向后删除:此过程从整个属性集开始。在每个步骤中,删除属性集中仍然存在的最差属性。
前向选择和后向删除的结合:前向选择和后向删除方法可以结合,每一步可以选择一个最佳属性,其余属性可以删除一个最差属性。
python scikit-learn中的递归特征消除算法(RFE)使用这一思想来过滤特征子集,并且通常考虑SVM或回归模型。
单变量重要性:分析单变量与目标变量的相关性,删除预测能力低的变量。这种方法不同于属性子集选择,通常从统计和信息的角度进行分析。
皮尔逊相关系数和卡方检验用于分析目标变量和单价变量之间的相关性。
ⅳ指数(IV Index):在风控制模型中,通常求解每个变量的ⅳ值来定义变量的重要性,阈值一般设定在0.02以上。
上述方法没有解释具体的理论知识和实施方法,这需要学生熟悉和掌握。业主的通常做法是根据业务要求来确定。如果需要根据企业用户或商品的特点进行更多的解释,可以考虑一些统计方法,如分布曲线和变量直方图,然后计算相关指标,最后考虑一些模型方法。
如果需要建模,建模方法通常用于筛选特征。如果使用更复杂的模型,如GBDT和DNN,建议进行要素交叉,而不是要素选择。
2、维度变换:
维度转换将现有数据缩减到更小的维度,以尽可能确保数据信息的完整性。建筑物所有者将引入几种常用的有损失的维度转换方法,这将极大地提高在实践中
主成分分析(PCA)和因子分析(FA)的建模效率:主成分分析通过空间映射将当前维度映射到较低的维度,从而使新空间中每个变量的方差最大化。FA是找到当前特征向量的公共因子(较小维度),并且使用公共因子的线性组合来描述当前特征向量。
奇异值分解:奇异值分解比主成分分析具有更低的降维解释能力和更大的计算量。它通常用于减少稀疏矩阵的维数,例如图像压缩和推荐系统。
数据转换包括数据的规范化、离散化和细化,以达到适合挖掘的目的。
1、规范化处理:数据中不同特征的尺寸可能不一致,值之间的差异可能非常大。处理失败可能会影响数据分析的结果。因此,需要按照一定的比例对数据进行缩放,使其落入特定的区域进行综合分析。特别是,基于距离的采矿方法、集群、KNN和SVM必须标准化。
2、离散化处理:数据离散化是指将连续数据分割成离散区间。分割的原则是基于等距离、等频率或优化方法。数据离散化的主要原因如下:
模型需求:决策树和朴素贝叶斯等算法都是基于离散数据扩展的。如果要使用这种算法,必须使用离散数据。有效的离散化可以减少算法的时间和空间开销,提高系统对样本的分类聚类能力和抗噪声能力。
离散特征比连续特征更容易理解。
能有效克服数据中隐藏的缺陷,使模型结果更加稳定。
3、稀疏化处理:对于离散变量和标称变量,当不能执行有序标签编码时,通常认为用0.1个虚拟变量使变量稀疏。例如,动物类型变量包含猫、狗、猪和羊的四个不同值,并且这些变量被转换成is_ pig、is_ catis_ dog和is_ sheep的四个虚拟变量。如果变量有许多不同的值,出现较少的值将根据频率统一为一个类别“罕见”。稀疏处理不仅有利于模型的快速收敛,而且提高了模型的抗噪声能力。
以上介绍了数据预处理中使用的大部分方法和技术,这些方法和技术完全适合初学者学习和掌握,将大大提高实际建模的水平。以上方法的代码实现可以在python的熊猫和sklearn中完成。每个人都可以根据自己的需要进行咨询和学习,并且有许多在线材料。房东只提供方法和经验供参考。我希望每个努力学习和巩固的学生都能得到提升。
极牛网精选文章《整理一份详细的数据预处理方法》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/3507.html
 微信公众号
微信公众号  微信小程序
微信小程序