当涉及到用于数据科学的python包时,人们会想到numpy、熊猫、scikit-learn等等。在这里,我想介绍一些不常用但非常有用的python包,就像草稿一样。虽然大部分时间不使用它们,但使用起来确实很酷。

Python是一种神奇的语言。事实上,这是世界上发展最快的语言之一。在数据科学和发展领域,它一次又一次地为我们提供了便利。整个Python生态系统和库使它适合所有用户(初学者和高级用户)。蟒蛇如此成功的原因之一是它的库使蟒蛇变得灵活而快速。
在本文中,我们将研究一些不常用的数据科学数据库,除了熊猫、scikit-learn、matplotlib等。虽然说到数据科学,我们想到熊猫和scikit-learn,但是了解其他python库并没有什么坏处。这里还有一些其他可以在数据科学中使用的Python库。
Wget
从网络获取数据对蟒蛇科学家来说是一项非常重要的任务。Wget是一个免费的工具,可以非交互地从网上下载文件。它支持超文本传输协议、HTTPS协议和文件传输协议,以及超文本传输协议代理。因为它是非交互式的,所以它可以在后台运行,用户也可以在不登录的情况下运行。所以下次你需要从网上下载图片时,你可以试试wget。
安装:
import wgeturl=’ http://www。未来的rew。com/skaven/song _ files/MP3/razor back。MP3文件名=wget。下载(网址)100%[……..]3841532/3841532文件名剃刀回来了。MP3 ‘
Pendulum
例子:
importwgeturl=’http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3’filename=wget.download(url)100%[……]3841532/3841532filename’razorback.mp3′
imbalanced-learn
这是干什么的?当你在处理日期和时间时变得很大时,钟摆非常适合你。这个包用来简化日期和时间的操作。详情请见此处。
安装:
pip安装-Uimbalanced-learn #或condans tall-cconda-forgeimbalanced-learn@
例子:
importpendulumdt_toronto=pendulum.datetime(2012,1,1,tz=’America/Toronto’)dt_vancouver=pendulum.datetime(2012,1,1,tz=’America/Vancouver’)print(dt_vancouver.diff(dt_toronto).in_hours())3
FlashText
在大多数分类问题中,当所有类别的样本数量大致相同时,效果最好,即样本均衡。然而,在实际情况下,数据往往是不平衡的,这往往会影响训练过程和后续的预测。幸运的是,这个图书馆可以帮助我们解决这个问题。这与scikit-learn兼容,是scikit-learn-contrib的一部分。你下次可以试试。
安装:
fromFlashTextImportKeyWordProcesworkyWard _ processor=KeyWordProcessor()# KeyWordProcessor。add _ keyword _ processor。添加关键字(未清除名称,标准化名称)关键字处理器。添加关键字处理器。add _ keyword _ keyword(‘ BigAPP)关键字_找到“[”纽约\ ‘ \ ‘巴亚区]
例子:
请参考文档。
Fuzzywuzzy
在清理与NLP相关的数据时,经常需要替换一些关键字或提取一些关键字。通常,您可以使用正则表达式来完成这项工作,但是当正则条件数为千时,它将非常大。FlashText是一个基于FlashText算法的模块,在这种情况下提供了一个替代工具。FlashText最大的优点是运行时与搜索条件的数量无关。更多信息可以在这里找到。
安装:
pipinstallpyflux@
例子:
提取关键词
替换关键词
keyword_processor.add_keyword(‘NewDelhi’,’NCRregion’)new_sentence=keyword_processor.replace_keywords(‘IloveBigAppleandnewdelhi.’)new_sentence’IloveNewYorkandNCRregion.’
PyFlux
name听起来很奇怪,但在匹配字符时仍然可以刷新使用。可以轻松实现字符缩放、令牌缩放等。您也可以在不同的数据集中进行匹配。
安装:
例子:
fromfuzzywuzzyimportfuzzfromfuzzywuzzyimportprocess#SimpleRatiofuzz.ratio(‘thisisatest’,’thisisatest!’)97#PartialRatiofuzz.partial_ratio(‘thisisatest’,’thisisatest!’)100
Ipyvolume
时间序列的处理是机器学习领域的一个常见问题。PyFlux是一个开源的Python库,致力于处理时间序列问题。该数据库有一系列的时间序列模型,如ARIMA、GARCH和VAR。简而言之,PyFlux为概率建模提供了一个时间序列,一个数值试验。
安装
例子
看这里。
Dash
交流结果是数据科学的一个非常重要的方面。结果可视化是一个非常重要的优势。IPyvolume是一个3D可视化库,但它仍处于1.0之前的阶段。可分以下几类:IPyvolume是3D数据的可视化,matplotlib是2D数据的可视化。细节可以在这里看到。
安装
例子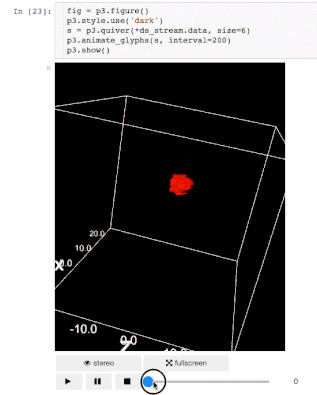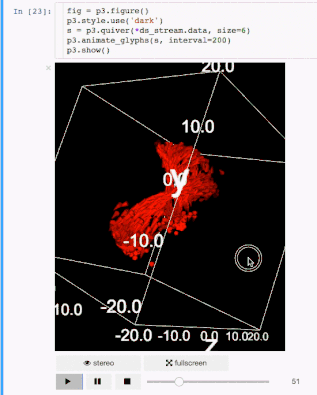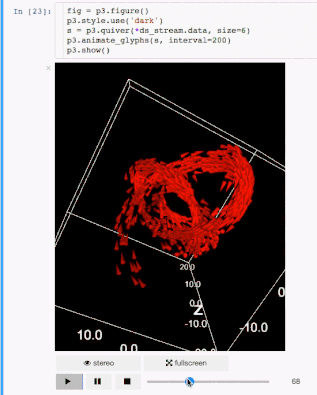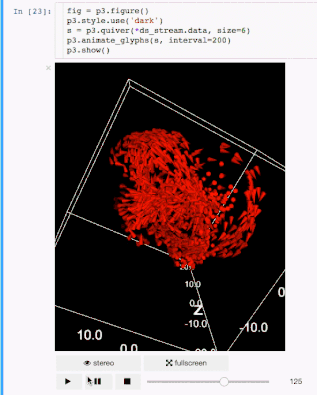 标记
标记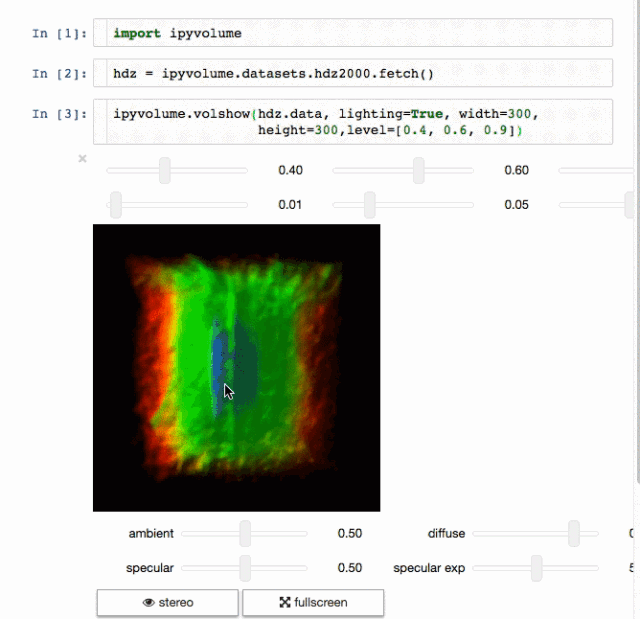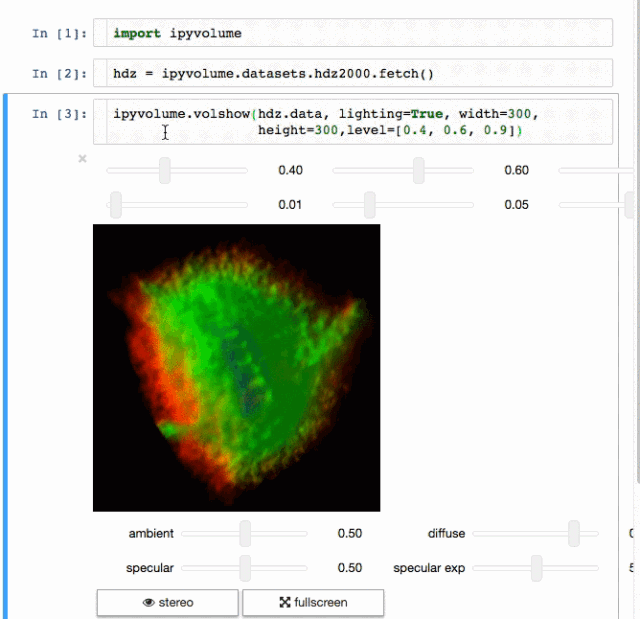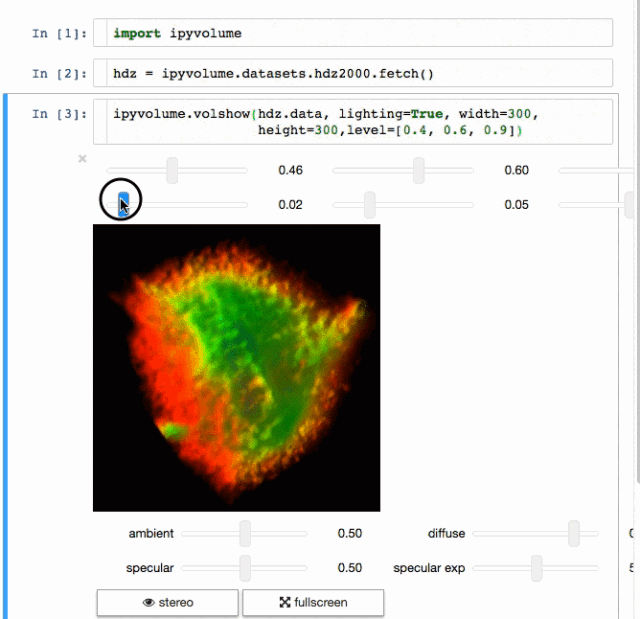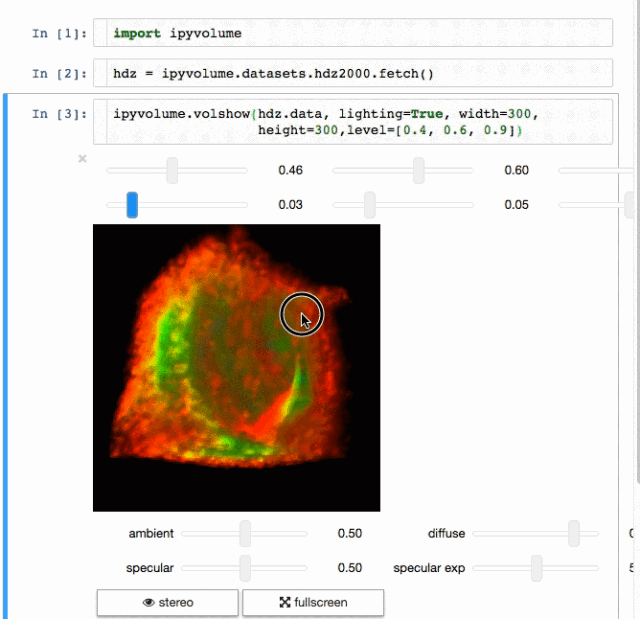
Gym
渲染
安装例子
结论
这是一个由创建网络应用程序的用户生成的Python框架。基于烧瓶编写的可用于构建数据可视化的应用程序,这些应用程序可在网络浏览器上呈现。用户手册可以在这里找到。
安装
pipinstallgym
例子
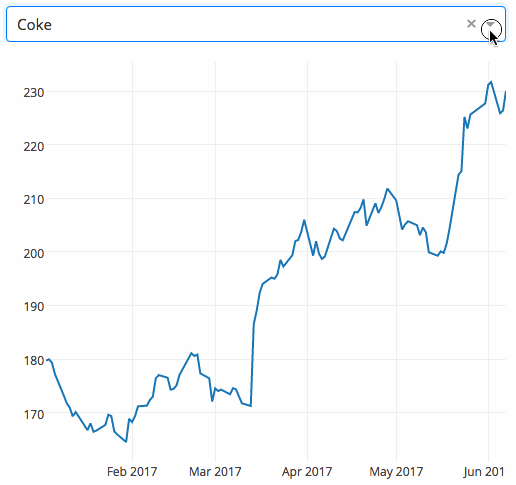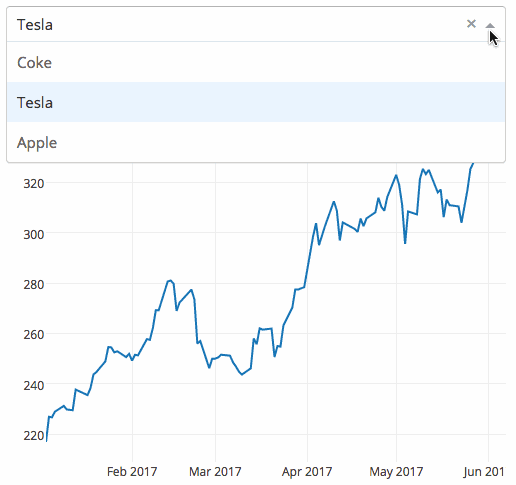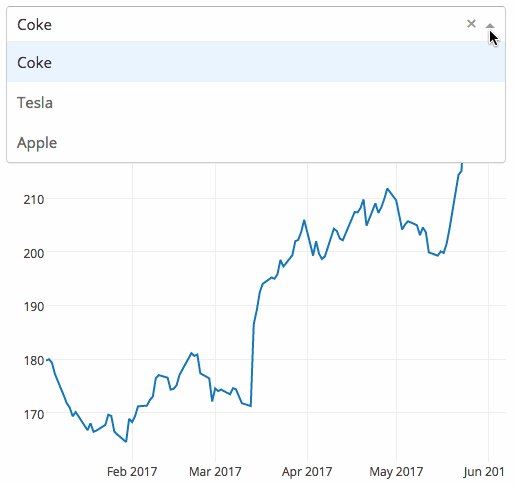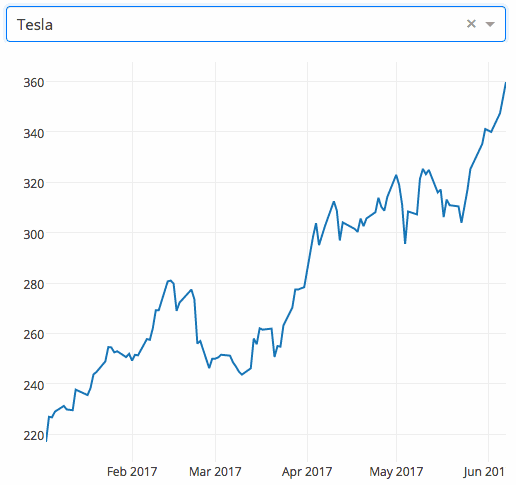
Gym来自OpenAI,用于强化学习。兼容所有数值计算库,如张量流(TensorFlow)、Anao等。这个库为问题测试提供了一个环境。您可以使用这个环境来实验您的强化学习算法。这些环境共享接口,因此您可以编写通用算法。
这些是我选择的一些有用但不常用的python库。如果你还知道别的,你可以继续添加它们。别忘了先试试。
极牛网精选文章《数据科学中一些不常用但很有用的Python库》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/3662.html
 微信公众号
微信公众号  微信小程序
微信小程序