我们都知道 Lambda 和 Stream 是 Java 8 的两大亮点功能,在前面的文章里已经介绍过 Lambda 相关知识,这次介绍下 Java 8 的 Stream 流操作。它完全不同于 java.io 包的 Input/Output Stream ,也不是大数据实时处理的 Stream 流。
这个 Stream 流操作是 Java 8 对集合操作功能的增强,专注于对集合的各种高效、便利、优雅的聚合操作。借助于 Lambda 表达式,显著的提高编程效率和可读性。且 Stream 提供了并行计算模式,可以简洁的编写出并行代码,能充分发挥如今计算机的多核处理优势。
1. Stream 流介绍
Stream 不同于其他集合框架,它也不是某种数据结构,也不会保存数据,但是它负责相关计算,使用起来更像一个高级的迭代器。在之前的迭代器中,我们只能先遍历然后在执行业务操作,而现在只需要指定执行什么操作, Stream 就会隐式的遍历然后做出想要的操作。另外 Stream 和迭代器一样的只能单向处理,如同奔腾长江之水一去而不复返。
由于 Stream 流提供了惰性计算和并行处理的能力,在使用并行计算方式时数据会被自动分解成多段然后并行处理,最后将结果汇总。所以 Stream 操作可以让程序运行变得更加高效。
2. Stream 流概念
Stream 流的使用总是按照一定的步骤进行,可以抽象出下面的使用流程。
数据源(source) -> 数据处理/转换(intermedia) -> 结果处理(terminal )
2.1. 数据源
数据源(source)也就是数据的来源,可以通过多种方式获得 Stream 数据源,下面列举几种常见的获取方式。
-
- Collection.stream(); 从集合获取流。 Collection.parallelStream(); 从集合获取
并行流。
- Arrays.stream(T array) or Stream.of(); 从数组获取流。 BufferedReader.lines(); 从输入流中获取流。 IntStream.of() ; 从静态方法中获取流。 Stream.generate(); 自己生成流
2.2. 数据处理
数据处理/转换(intermedia)步骤可以有多个操作,这步也被称为intermedia(中间操作)。在这个步骤中不管怎样操作,它返回的都是一个新的流对象,原始数据不会发生任何改变,而且这个步骤是惰性计算处理的,也就是说只调用方法并不会开始处理,只有在真正的开始收集结果时,中间操作才会生效,而且如果遍历没有完成,想要的结果已经获取到了(比如获取第一个值),会停止遍历,然后返回结果。惰性计算可以显著提高运行效率。
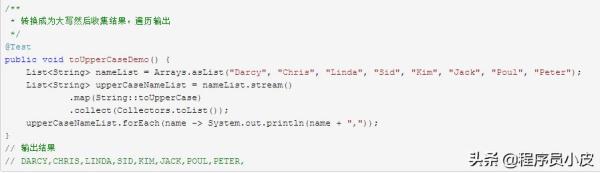
数据处理演示。

数据处理/转换操作自然不止是上面演示的过滤 filter 和 map映射两种,另外还有 map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered 等。
2.3. 收集结果
结果处理(terminal )是流处理的最后一步,执行完这一步之后流会被彻底用尽,流也不能继续操作了。也只有到了这个操作的时候,流的数据处理/转换等中间过程才会开始计算,也就是上面所说的惰性计算。结果处理也必定是流操作的最后一步。
常见的结果处理操作有 forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator 等。
下面演示了简单的结果处理的例子。
2.4. short-circuiting
有一种 Stream 操作被称作 short-circuiting ,它是指当 Stream 流无限大但是需要返回的 Stream 流是有限的时候,而又希望它能在有限的时间内计算出结果,那么这个操作就被称为short-circuiting。例如 findFirst 操作。
3. Stream 流使用
Stream 流在使用时候总是借助于 Lambda 表达式进行操作,Stream 流的操作也有很多种方式,下面列举的是常用的 11 种操作。
3.1. Stream 流获取
获取 Stream 的几种方式在上面的 Stream 数据源里已经介绍过了,下面是针对上面介绍的几种获取 Stream 流的使用示例。

3.2. forEach
forEach 是 Strean 流中的一个重要方法,用于遍历 Stream 流,它支持传入一个标准的 Lambda 表达式。但是它的遍历不能通过 return/break 进行终止。同时它也是一个 terminal 操作,执行之后 Stream 流中的数据会被消费掉。
如输出对象。

3.3. map / flatMap
使用 map 把对象一对一映射成另一种对象或者形式。
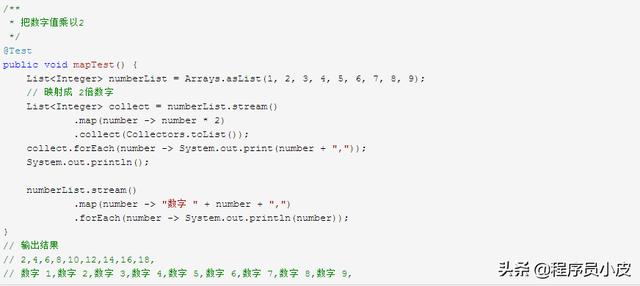
上面的 map 可以把数据进行一对一的映射,而有些时候关系可能不止 1对 1那么简单,可能会有1对多。这时可以使用 flatMap。下面演示使用 flatMap把对象扁平化展开。

3.4. filter
使用 filter 进行数据筛选,挑选出想要的元素,下面的例子演示怎么挑选出偶数数字。

得到如下结果。
2,4,6,8,
3.5. findFirst
findFirst 可以查找出 Stream 流中的第一个元素,它返回的是一个 Optional 类型,如果还不知道 Optional 类的用处,可以参考之前文章 Jdk14都要出了,还不能使用 Optional优雅的处理空指针? 。

findFirst 方法在查找到需要的数据之后就会返回不再遍历数据了,也因此 findFirst 方法可以对有无限数据的 Stream 流进行操作,也可以说 findFirst 是一个 short-circuiting 操作。
3.6. collect / toArray
Stream 流可以轻松的转换为其他结构,下面是几种常见的示例。

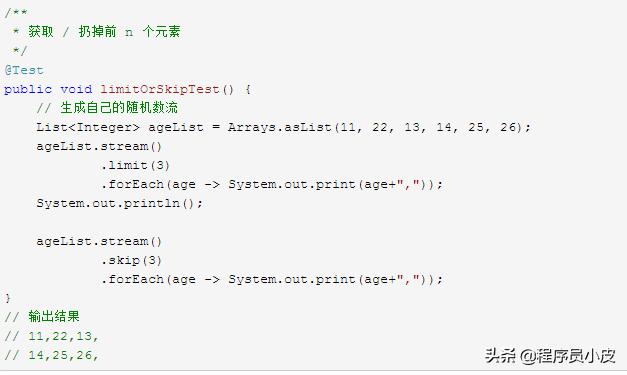
3.7. limit / skip
获取或者扔掉前 n 个元素
3.8. Statistics
数学统计功能,求一组数组的最大值、最小值、个数、数据和、平均数等。

3.9. groupingBy
分组聚合功能,和数据库的 Group by 的功能一致。

3.10. partitioningBy

3.11. 进阶 – 自己生成 Stream 流
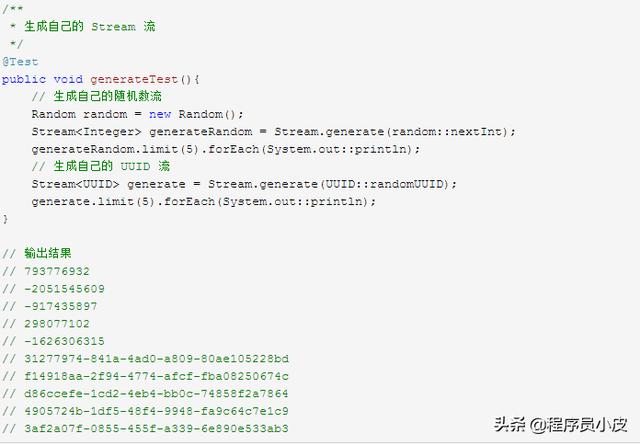
上面的例子中 Stream 流是无限的,但是获取到的结果是有限的,使用了 Limit 限制获取的数量,所以这个操作也是 short-circuiting 操作。
4. Stream 流优点
4.1. 简洁优雅
正确使用并且正确格式化的 Stream 流操作代码不仅简洁优雅,更让人赏心悦目。下面对比下在使用 Stream 流和不使用 Stream 流时相同操作的编码风格。
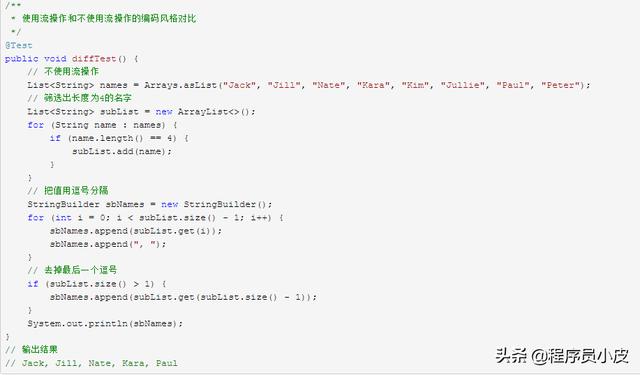
如果是使用 Stream 流操作。

4.2. 惰性计算
上面有提到,数据处理/转换(intermedia) 操作 map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered 等这些操作,在调用方法时并不会立即调用,而是在真正使用的时候才会生效,这样可以让操作延迟到真正需要使用的时刻。
下面会举个例子演示这一点。
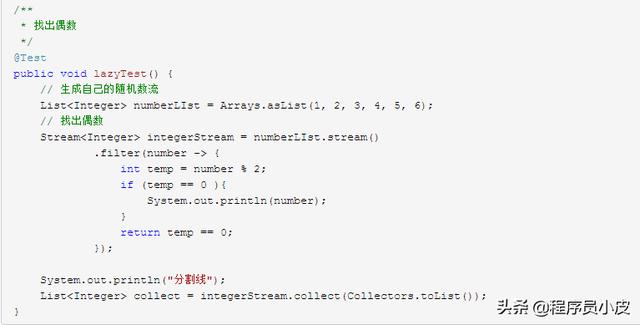
如果没有 惰性计算,那么很明显会先输出偶数,然后输出 分割线。而实际的效果是。
可见 惰性计算 把计算延迟到了真正需要的时候。
4.3. 并行计算
获取 Stream 流时可以使用 parallelStream 方法代替 stream 方法以获取并行处理流,并行处理可以充分的发挥多核优势,而且不增加编码的复杂性。
下面的代码演示了生成一千万个随机数后,把每个随机数乘以2然后求和时,串行计算和并行计算的耗时差异。

得到如下输出。

效果显而易见,代码简洁优雅。
5. Stream 流建议
5.1 保证正确排版
从上面的使用案例中,可以发现使用 Stream 流操作的代码非常简洁,而且可读性更高。但是如果不正确的排版,那么看起来将会很糟糕,比如下面的同样功能的代码例子,多几层操作呢,是不是有些让人头大?

5.1 保证函数纯度
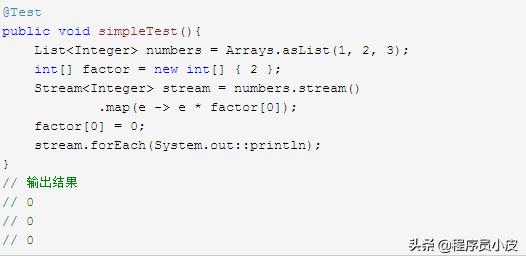
如果想要你的 Stream 流对于每次的相同操作的结果都是相同的话,那么你必须保证 Lambda 表达式的纯度,也就是下面亮点。
- Lambda 中不会更改任何元素。 Lambda 中不依赖于任何可能更改的元素。
这两点对于保证函数的幂等非常重要,不然你程序执行结果可能会变得难以预测,就像下面的例子。
极牛网精选文章《看不懂同事的代码?超强的 Stream 流操作姿势还不学习一下》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/6104.html
 微信公众号
微信公众号  微信小程序
微信小程序