
前 言
本标准依据GB/T 1.1-2020《标准化工作导则 第1部分:标准化文件的结构和起草规则》的规定起草。
大语言模型等AI大模型的广泛应用,在带来巨大生产力的同时,也引入了全新的安全挑战。针对模型应用的提示词注入、数据泄露、恶意内容生成及模型滥用等攻击手段日益增多,传统网络安全防护措施难以有效应对。
AI大模型应用防火墙(AI-MAF)作为部署在用户与大模型应用之间的专用安全防护组件,通过实时检测、过滤和阻断恶意交互,成为保障大模型应用安全、可靠、合规运行的关键基础设施。为规范本公司AI-MAF产品的设计、开发、测试与部署,确保其防护能力满足企业级安全需求,特制定本标准。
本标准由深圳市蓝典信安科技有限公司提出并起草。
本标准起草部门:深圳市蓝典信安科技有限公司人工智能实验室
本标准主要起草人:叶绍琛、蔡国兆、黎治声、揭育奎、韩江、陈丹玲
本标准于2025年12月3日首次发布。
AI大模型应用防火墙技术规范
1 范围
本标准规定了AI大模型应用防火墙(以下简称“AI-MAF”)的技术要求,包括总体架构、核心功能、安全策略、管理运维及符合性测试等内容。
本标准适用于指导企业进行AI-MAF的规划、设计、开发、选型、部署、运维和评估,旨在防范与大模型应用相关的数据泄露、内容安全、模型滥用及业务风险。
2 规范性引用文件
下列文件对于本文件的应用是必不可少的。凡是注日期的引用文件,仅注日期的版本适用于本文件。凡是不注日期的引用文件,其最新版本(包括所有的修改单)适用于本文件。
GB/T 22239-2019 信息安全技术 网络安全等级保护基本要求
GB/T 35273-2020 信息安全技术 个人信息安全规范
国家互联网信息办公室等《生成式人工智能服务管理暂行办法》
3 术语和定义
下列术语和定义适用于本文件。
3.1 AI大模型应用 AI Large Model Application
基于大规模预训练模型(如LLM、多模态模型)构建,提供文本生成、对话、内容分析、代码生成等能力的软件系统。
3.2 AI大模型应用防火墙 AI LLM Application Firewall (AI-MAF)
部署于用户/客户端与大模型服务之间,对双向流量进行监控、分析、过滤和管控的安全代理组件或系统。
3.3 提示词注入 Prompt Injection
通过精心构造的用户输入,诱导大模型突破预设指令、泄露敏感信息或执行非授权操作的安全攻击手段。
3.4 训练数据泄露 Training Data Extraction
攻击者通过特定查询,诱导大模型回复其训练数据中包含的、本不应公开的敏感信息。
4 总体要求
4.1 架构原则
AI-MAF应采用代理架构,支持串联或旁路部署模式。系统应具备高可用性、可扩展性和低延迟特性,不应成为大模型应用的单点故障或性能瓶颈。
4.2 安全目标
AI-MAF应实现以下核心安全目标:
- a) 数据安全:防止敏感数据(如PII、商业秘密、源码)通过用户输入或模型输出泄露。
- b) 内容安全:过滤违法违规、歧视偏见、不道德及与业务场景无关的输入与输出内容。
- c) 资源防护:防止恶意调用导致的资源耗尽、模型滥用及API经济性攻击。
- d) 合规审计:满足数据出境、个人信息保护、生成内容标识等监管要求。
4.3 性能要求
在典型业务负载下,AI-MAF对单次请求-响应的处理延迟应低于100毫秒,吞吐量应能满足上游应用的最大并发需求。
5 功能要求
5.1 输入侧防护
5.1.1 身份认证与访问控制
应支持对接企业统一身份认证系统(如IAM、OAUTH 2.0)。
应具备细粒度访问控制能力,可基于用户、角色、部门、时间段等属性限制对特定模型或API端点的访问频率和总量。
5.1.2 提示词安全检测
应能实时检测并阻断提示词注入攻击(如系统指令覆盖、越狱攻击)。
应支持对用户输入进行意图分类,识别并告警或阻断与业务无关的高风险请求(如模型角色扮演、内部指令探测)。
5.1.3 敏感信息过滤
应内置或可自定义敏感信息识别规则(如正则表达式、关键词、数据指纹),对输入文本中的身份证号、银行卡号、密钥、核心代码等进行实时脱敏或阻断。
应支持与数据分类分级系统联动,依据数据级别执行不同的控制策略。
5.1.4 内容安全过滤
应能对输入内容进行违法违规信息识别,参照《网络信息内容生态治理规定》等要求。
5.2 输出侧防护
5.2.1 输出内容安全过滤
应对模型生成的内容进行二次安全审查,过滤其中的违法违规、歧视性、攻击性信息。
应具备“幻觉”缓解能力,可对模型生成的关键事实声明(如人物、事件、数据)进行可信度标记或警示。
5.2.2 敏感信息防泄露
应对模型输出进行扫描,防止训练数据泄露或输入中的脱敏信息在输出中被逆向还原。
应能检测并阻断模型生成的恶意代码、钓鱼链接等。
5.2.3 格式与结构化输出校验
应能对模型承诺的结构化输出(如JSON、XML)进行语法和模式(Schema)校验,防止畸形输出导致下游系统故障。
5.3 审计与监控
5.3.1 全链路日志
应记录所有请求和响应的元数据(如时间戳、用户ID、模型ID、Token用量)。
应支持对敏感操作和策略匹配事件进行详细日志记录,日志保存时间不少于[例如:180]天。
5.3.2 实时监控与告警
应提供可视化仪表盘,展示调用量、延迟、异常请求率、策略命中率等关键指标。
应配置实时告警规则,对异常流量、高频敏感操作、系统故障等事件及时通知管理员。
5.3.3 溯源分析
应支持基于会话ID或用户ID,对完整的交互会话进行溯源查询,关联查看输入、输出及触发的安全事件。
6 管理要求
6.1 策略管理
应提供图形化策略管理界面,支持安全策略(如黑白名单、正则规则、语义规则)的灵活配置、启用、禁用和版本管理。
策略应支持按不同模型、不同用户组进行差异化配置。
6.2 系统管理
应具备完善的系统管理功能,包括管理员角色分权、操作日志、系统配置备份与恢复。
应定期进行系统漏洞扫描与安全评估。
6.3 模型与知识库管理
应与企业的模型管理平台联动,及时同步已上线模型列表与访问端点。
可支持对接外部威胁情报或安全知识库,用于更新恶意提示词模式等。
7 符合性测试
7.1 测试环境
应搭建与生产环境相似的测试环境,包含AI-MAF、模拟大模型服务及测试客户端。
7.2 功能符合性测试
依据第5章的功能要求,设计测试用例,验证各项防护功能的有效性。例如:
注入测试:验证是否能阻断典型的提示词注入攻击。
过滤测试:验证输入/输出中的敏感信息是否能被准确识别和处置。
性能测试:在额定负载下,验证系统延迟与吞吐量是否符合4.3要求。
7.3 审计符合性测试
验证日志记录的完整性、准确性和可查询性,以及告警功能是否按预期触发。
附录 A
(资料性附录)
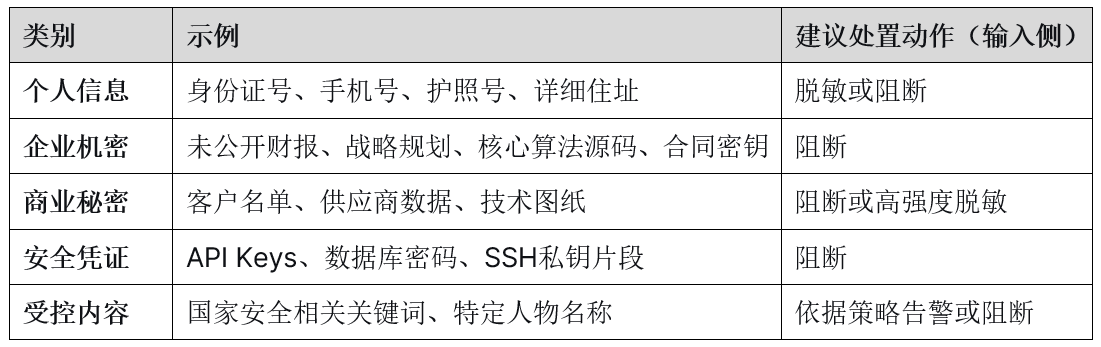
敏感信息分类示例

极牛网精选文章《Q/GDLS 27003-2025《AI大模型应用防火墙技术规范》技术标准》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/28482.html
 微信公众号
微信公众号  微信小程序
微信小程序 







