DevOps 实践中,我们在 CI(Continuous Integration) 持续集成过程主要包含了代码提交、静态检测、单元测试、编译打包环节。其中静态代码检测可以在编码规范,代码缺陷,性能等问题上提前预知,从而保证项目的交付质量。Android 项目常用的静态扫描工具包括 CheckStyle、Lint、FindBugs 等,为降低接入成本,美团内部孵化了静态代码扫描插件,集合了以上常用的扫描工具。

项目初期引入集团内部基建时我们接入了代码扫描插件,在 PR(Pull Request) 流程中借助 Jenkins 插件来触发自动化构建,从而达到监控代码质量的目的。初期单次构建耗时平均在 1~2min 左右,对研发效率影响甚少。但是随着时间推移,代码量随业务倍增,项目也开始使用 Flavor 来满足复杂的需求,这使得我们的单次 PR 构建达到了8~9min左右,其中静态代码扫描的时长约占50%,持续集成效率不高,对我们的研发效率带来了挑战。
思考与策略
针对以上的背景和问题,我们思考以下几个问题:
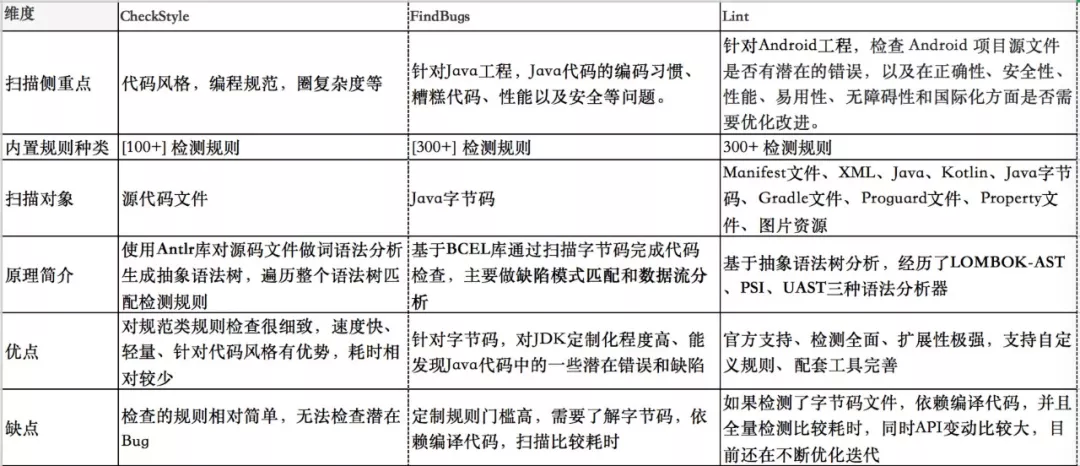
思考一:现有插件包含的扫描工具是否都是必需的?扫描工具对比
为了验证扫描工具的必要性,我们关心以下一些维度:
- 扫码侧重点,对比各个工具分别能针对解决什么类型的问题;
- 内置规则种类,列举各个工具提供的能力覆盖范围;
- 扫描对象,对比各个工具针对什么样的文件类型扫描;
- 原理简介,简单介绍各个工具的扫描原理;
- 优缺点,简单对比各个工具扫描效率、扩展性、定制性、全面性上的表现。
注:FindBugs 只支持 Java1.0~1.8,已经被 SpotBugs 替代。鉴于部分老项目并没有迁移到 Java8,目前我们并没有使用 SpotBugs 代替 FindBugs 的原因如下,详情参考官方文档。

同时,SpotBugs 的作者也在讨论是否让 SpotBugs 支持老的 Java 版本,结论是不提供支持。
经过以上的对比分析我们发现,工具的诞生都能针对性解决某一领域问题。CheckStyle 的扫描速度快效率高,对代码风格和圈复杂度支持友好;FindBugs 针对 Java 代码潜在问题,能帮助我们发现编码上的一些错误实践以及部分安全问题和性能问题;Lint 是官方深度定制,功能极其强大,且可定制性和扩展性以及全面性都表现良好。所以综合考虑,针对思考一,我们的结论是整合三种扫描工具,充分利用每一个工具的领域特性。
思考二:是否可以优化扫描过程?
既然选择了整合这几种工具,我们面临的挑战是整合工具后扫描效率的问题,首先来分析目前的插件到底耗时在哪里。
静态代码扫描耗时分析
Android 项目的构建依赖 Gradle 工具,一次构建过程实际上是执行所有的 Gradle Task。由于 Gradle 的特性,在构建时各个 Module 都需要执行 CheckStyle、FindBugs、Lint 相关的 Task。对于 Android 来说,Task 的数量还与其构建变体 Variant 有关,其中 Variant = Flavor * BuildType。所以一个 Module 执行的相关任务可以由以下公式来描述:Flavor * BuildType *(Lint,CheckStyle,Findbugs),其中 * 为笛卡尔积。如下图所示:
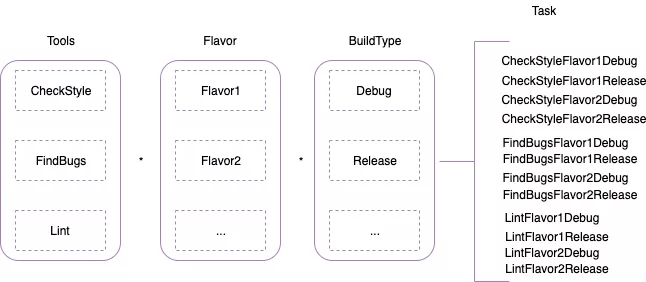
可以看到,一次构建全量扫描执行的 Task 跟 Varint 个数正相关。对于现有工程的任务,我们可以看一下目前各个任务的耗时情况:(以实际开发中某一次扫描为例)
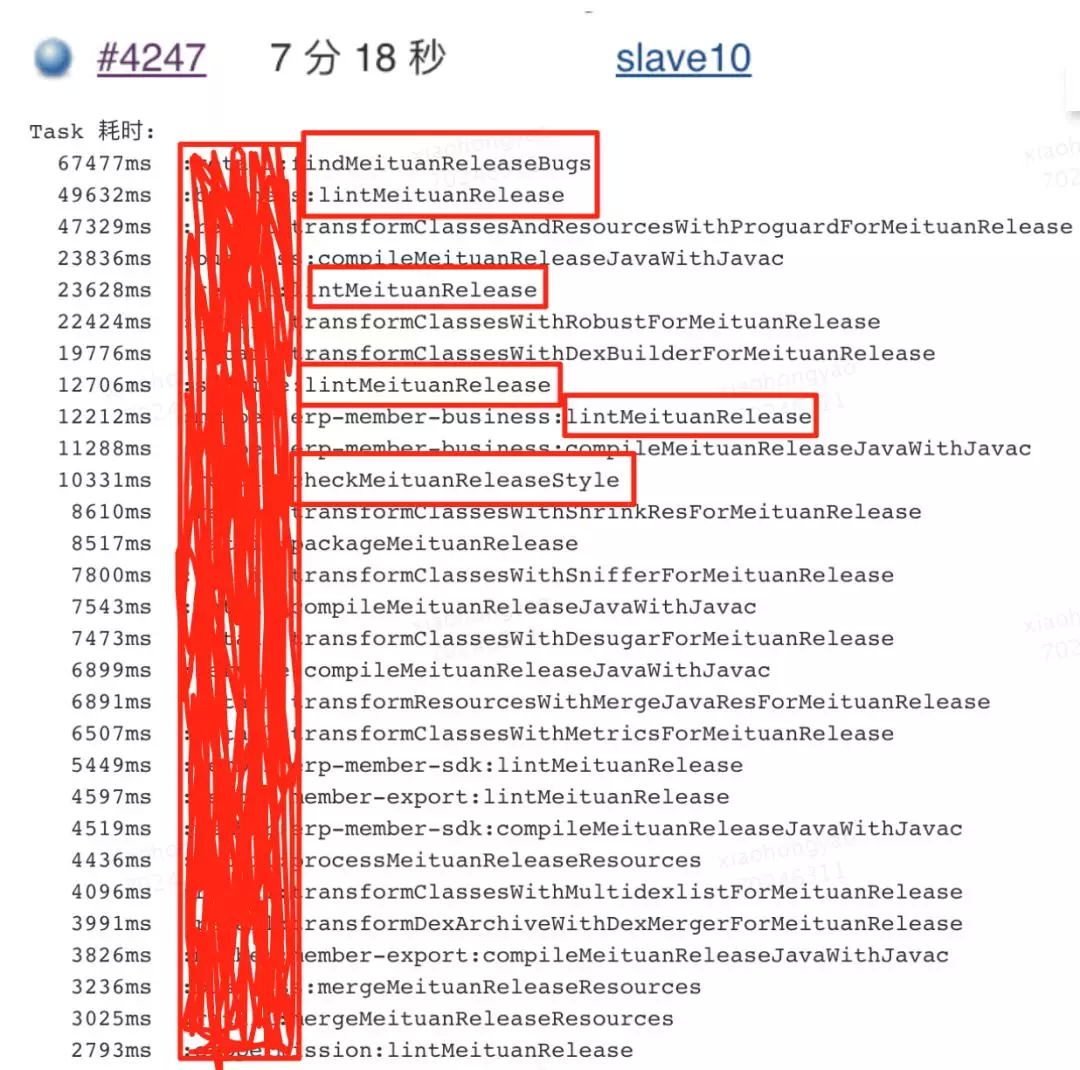
通过对 Task 耗时排序,主要的耗时体现在 FindBugs 和 Lint 对每一个 Module 的扫描任务上,CheckStyle 任务并不占主要影响。整体来看,除了工具本身的扫描时间外,耗时主要分为多 Module、多 Variant 带来的任务数量耗时。
优化思路分析
对于工具本身的扫描时间,一方面受工具自身扫描算法和检测规则的影响,另一方面也跟扫描的文件数量相关。针对源码类型的工具比如 CheckStyle 和 Lint,需要经过词法分析、语法分析生成抽象语法树,再遍历抽象语法树跟定义的检测规则去匹配;而针对字节码文件的工具 FindBugs,需要先编译源码成 Class 文件,再通过 BCEL 分析字节码指令并与探测器规则匹配。如果要在工具本身算法上去寻找优化点,代价比较大也不一定能找到有效思路,投入产出比不高,所以我们把精力放在减少 Module 和 Variant 带来的影响上。
从上面的耗时分析可以知道,Module 和 Variant 数直接影响任务数量, 一次 PR 提交的场景是多样的,比如多 Module 多 Variant 都有修改,所以要考虑这些都修改的场景。先分析一个 Module 多 Variant 的场景,考虑到不同的 Variant 下源代码有一定差异,并且 FindBugs 扫描针对的是 Class 文件,不同的 Variant 都需要编译后才能扫描,直接对多 Variant 做处理比较复杂。我们可以简化问题,用以空间换时间的方式,在提交 PR 的时候根据 Variant 用不同的 Jenkins Job 来执行每一个 Variant 的扫描任务。所以接下来的问题就转变为如何优化在扫描单个 Variant 的时候多 Module 任务带来的耗时。
对于 Module 数而言,我们可以将其抽取成组件,拆分到独立仓库,将扫描任务拆分到各自仓库的变动时期,以 aar 的形式集成到主项目来减少 Module 带来的任务数。那对于剩下的 Module 如何优化呢?无论是哪一种工具,都是对其输入文件进行处理,CheckStyle 对 Java 源代码文件处理,FindBugs 对 Java 字节码文件处理,如果我们可以通过一次任务收集到所有 Module 的源码文件和编译后的字节码文件,我们就可以减少多 Module 的任务了。所以对于全量扫描,我们的主要目标是来解决如何一次性收集所有 Module 的目标文件。
思考三:是否支持增量扫描?
上面的优化思路都是基于全量扫描的,解决的是多 Module 多 Variant 带来的任务数量耗时。前面提到,工具本身的扫描时间也跟扫描的文件数量有关,那么是否可以从扫描的文件数量来入手呢?考虑平时的开发场景,提交 PR 时只是部分文件修改,我们没必要把那些没修改过的存量文件再参与扫描,而只针对修改的增量文件扫描,这样能很大程度降低无效扫描带来的效率问题。有了思路,那么我们考虑以下几个问题:
- 如何收集增量文件,包括源码文件和 Class 文件?
- 现在业界是否有增量扫描的方案,可行性如何,是否适用我们现状?
- 各个扫描工具如何来支持增量文件的扫描?根据上面的分析与思考路径,接下来我们详细介绍如何解决上述问题。
优化探索与实践全量扫描优化搜集所有 Module 目标文件集
获取所有 Module 目标文件集,首先要找出哪些 Module 参与了扫描。一个 Module 工程在 Gradle 构建系统中被描述为一个“Project”,那么我们只需要找出主工程依赖的所有 Project 即可。由于依赖配置的多样性,我们可以选择在某些 Variant 下依赖不同的 Module,所以获取参与一次构建时与当前 Variant 相关的 Project 对象
对于 Lint 工具而言,相应的 Lint Task 并没有相关属性可以指定扫描文件,所以在全量扫描上,我们暂时没有针对 Lint 做优化。
全量扫描优化数据
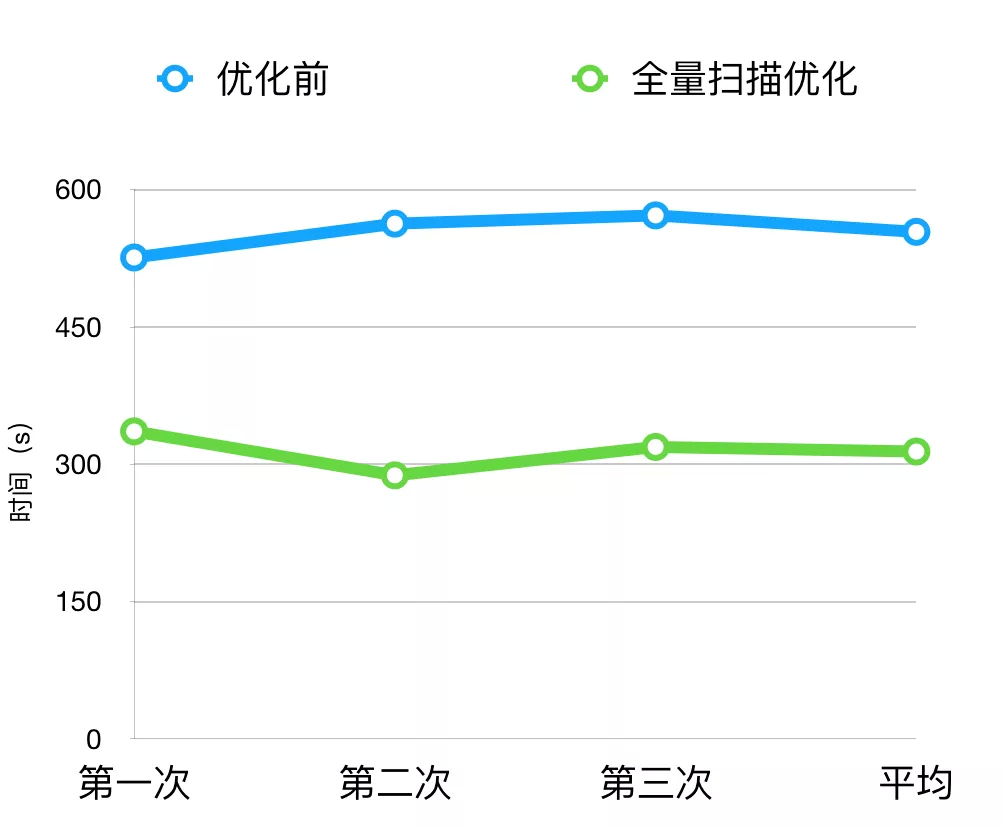
通过对 CheckStyle 和 FindBugs 全量扫描的优化,我们将整体扫描时间由原来的9min 降低到了 5min左右。
增量扫描优化
由前面的思考分析我们知道,并不是所有的文件每次都需要参与扫描,所以我们可以通过增量扫描的方式来提高扫描效率。
增量扫描技术调研
在做具体技术方案之前,我们先调研一下业界的现有方案,调研如下:

针对 Lint,我们可以借鉴现有实现思路,同时深入分析扫描原理,在 3.x 版本上寻找出增量扫描的解决方案。对于 CheckStyle 和 FindBugs,我们需要了解工具的相关配置参数,为其指定特定的差异文件集合。
注:业界有一些增量扫描的案例,例如 diff_cover ,此工具主要是对单元测试整体覆盖率的检测,以增量代码覆盖率作为一个指标来衡量项目的质量,但是这跟我们的静态代码分析的需求不太符合。它有一个比较好的思路是找出差异的代码行来分析覆盖率,粒度比较细。但是对于静态代码扫描,仅仅的差异行不足以完成上下文的语义分析,尤其是针对 FindBugs 这类需要分析字节码的工具,获取的差异行还需要经过编译成 Class 文件才能进行分析,方案并不可取。
寻找增量修改文件
增量扫描的第一步是获取待扫描的目标文件。我们可以通过git diff命令来获取差异文件,值得注意的是对于删除的文件和重命名的文件需要忽略,我们更关心新增和修改的文件,并且只需要获取差异文件的路径就好了。举个例子:git diff –name-only –diff-filter=dr commitHash1 commitHash2,以上命令意思是对比两次提交记录的差异文件并获取路径,过滤删除和重命名的文件。对于寻找本地仓库的差异文件上面的命令已经足够了,但是对于 PR 的情况还有一些复杂,需要对比本地代码与远程仓库目标分支的差异。集团的代码管理工具在 Jenkins 上有相应的插件,该插件默认提供了几个参数,我们需要用到以下两个:
- ${targetBranch}:需要合入代码的目标分支地址;
- ${sourceCommitHash}:需要提交的代码 hash 值。
通过这两个参数执行以下一系列命令来获取与远程目标分支的差异文件。
-
-
- 配置远程分支别名为 UpStream,其中 upstreamGitUrl 可以在插件提供的配置属性中设置;
- 获取远程目标分支的更新;
- 比较分支差异获取文件路径。通过以上方式,我们找到了增量修改文件集。
-
Lint 扫描原理分析
在分析 Lint 增量扫描原理之前,先介绍一下 Lint 扫描的工作流程:
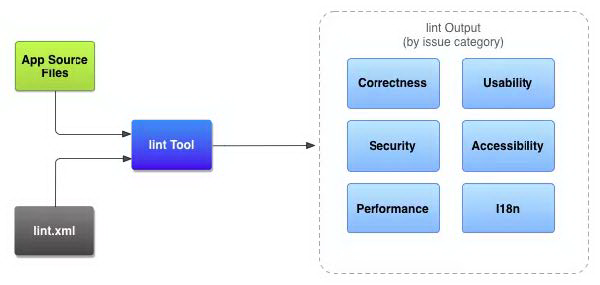
App Source Files
项目中的源文件,包括 Java、XML、资源文件、proGuard 等。
lint.xml
用于配置希望排除的任何 Lint 检查以及自定义问题严重级别,一般各个项目都会根据自身项目情况自定义的 lint.xml 来排除一些检查项。
lint Tool
一套完整的扫描工具用于对 Android 的代码结构进行分析,可以通过命令行、IDEA、Gradle 命令三种方式运行 lint 工具。
lint Output>
Lint 扫描的输出结果。
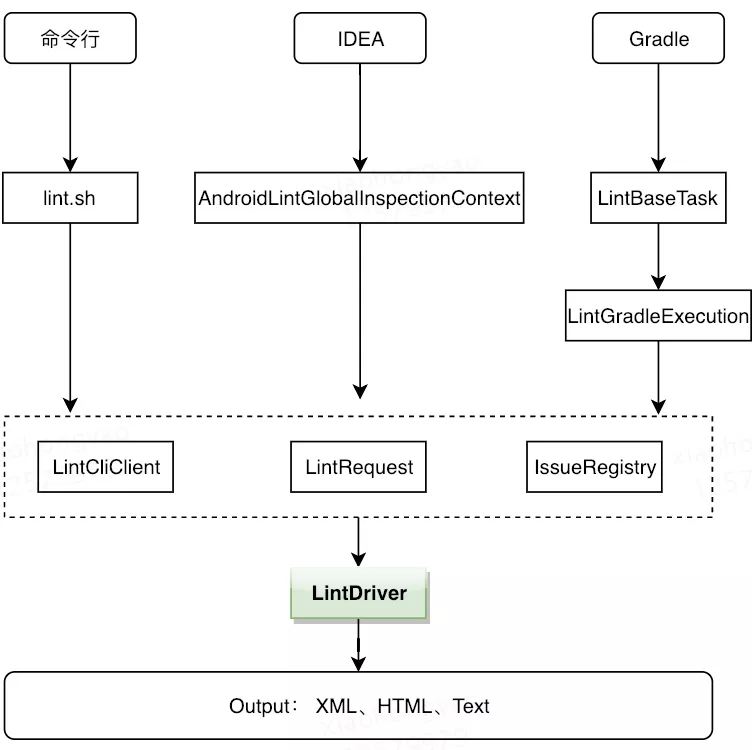
从上面可以看出,Lint Tool 就像一个加工厂,对投入进来的原料(源代码)进行加工处理(各种检测器分析),得到最终的产品(扫描结果)。Lint Tool 作为一个扫描工具集,有多种使用方式。Android 为我们提供了三种运行方式,分别是命令行、IDEA、Gradle 任务。这三种方式最终都殊途同归,通过LintDriver来实现扫描。如下图所示:
为了方便查看源码,新建一个工程,在 build.gradle 脚本中,添加如下依赖:
我们可以得到如下所示的依赖:
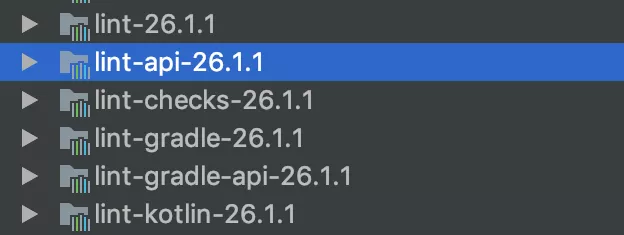
lint-api-26.1.1
Lint 工具集的一个封装,实现了一组 API 接口,用于启动 Lint。
lint-checks-26.1.1
一组内建的检测器,用于对这种描述好 Issue 进行分析处理。
lint-26.1.1
可以看做是依赖上面两个 jar 形成的一个基于命令行的封装接口形成的脚手架工程,我们的命令行、Gradle 任务都是继承自这个 jar 包中相关类来做的实现。
lint-gradle-26.1.1
可以看做是针对 Gradle 任务这种运行方式,基于 lint-26.1.1 做了一些封装类。
lint-gradle-api-26.1.1
真正 Gradle Lint 任务在执行时调用的入口。
在理解清楚了以上几个 jar 的关系和作用之后,我们可以发现 Lint 的核心库其实是前三个依赖。后面两个其实是基于脚手架,对 Gradle 这种运行方式做的封装。最核心的逻辑在LintDriver的Analyze方法中。
主要是以下三个重要步骤:
registerCustomDetectors(projects)
Lint 为我们提供了许多内建的检测器,除此之外我们还可以自定义一些检测器,这些都需要注册进 Lint 工具用于对目标文件进行扫描。这个方法主要做以下几件事情:
-
-
- 遍历每一个 Project 和它的依赖 Library 工程,通过 client.findRuleJars 来找出自定义的 jar 包;
- 通过 client.findGlobalRuleJars 找出全局的自定义 jar 包,可以作用于每一个 Android 工程;
- 从找到的 jarFiles 列表中,解析出自定义的规则,并与内建的 Registry 一起合并为 CompositeIssueRegistry;需要注意的是,自定义的 Lint 的 jar 包存放位置是build/intermediaters/lint目录,如果是需要每一个工程都生效,则存放位置为~/.android/lint/。
-
computeDetectors(project)
这一步主要用来收集当前工程所有可用的检测器。checkProject(project, main)接下来这一步是最为关键的一步。在此方法中,调用 runFileDetectors 来进行文件扫描。Lint 支持的扫描文件类型很多,因为是官方支持,所以针对 Android 工程支持的比较友好。一次 Lint 任务运行时,Lint 的扫描范围主要由Scope来描述。
如果 Project 的 Subset 不为 Null,就遍历 Subset 的集合,找出 Subset 中的文件分别对应哪些范围。其实到这里我们已经可以知道,Subset就是我们增量扫描的突破点。接下来我们看一下 runFileDetectors:
如果 project.subset 不为空,就对单独的 Java 文件扫描,否则,就对源码文件和测试目录以及自动生成的代码目录进行扫描。整个 runFileDetectors 的扫描顺序入下:
-
-
- Scope.MANIFEST
- Scope.ALL_RESOURCE_FILES)|| scope.contains(Scope.RESOURCE_FILE) || scope.contains(Scope.RESOURCE_FOLDER) || scope.contains(Scope.BINARY_RESOURCE_FILE)
- scope.contains(Scope.JAVA_FILE) || scope.contains(Scope.ALL_JAVA_FILES)
- scope.contains(Scope.CLASS_FILE) || scope.contains(Scope.ALL_CLASS_FILES) || scope.contains(Scope.JAVA_LIBRARIES)
- scope.contains(Scope.GRADLE_FILE)
- scope.contains(Scope.OTHER)
- scope.contains(Scope.PROGUARD_FILE)
- scope.contains(Scope.PROPERTY_FILE)
-
与 [官方文档] 的描述顺序一致。
现在我们已经知道,增量扫描的突破点其实是需要构造project.subset对象。
说明了只要 Files 不为 Null,就会扫描指定文件,否则扫描整个工程。
Lint 增量扫描 Gradle 任务实现
前面分析了如何获取差异文件以及增量扫描的原理,分析的重点还是侧重在 Lint 工具本身的实现机制上。接下来分析,在 Gradle 中如何实现一个增量扫描任务。大家知道,通过执行./gradlew lint 命令来执行 Lint 静态代码检测任务。创建一个新的 Android 工程,在 Gradle 任务列表中可以在 Verification 这个组下面找到几个 Lint 任务,如下所示:
这几个任务就是 Android Gradle 插件在加载的时候默认创建的。分别对应于以下几个 Task:
-
-
- lint->LintGlobalTask:由 TaskManager 创建;
- lintDebug、lintRelease、lintVitalRelease->LintPerVariantTask:由 ApplicationTaskManager 或者 LibraryTaskManager 创建,其中 lintVitalRelease 只在 release 下生成。
-
所以,在 Android Gradle 插件中,应用于 Lint 的任务分别为 LintGlobalTask 和 LintPerVariantTask。他们的区别是前者执行的是扫描所有 Variant,后者执行只针对单独的 Variant。而我们的增量扫描任务其实是跟 Variant 无关的,因为我们会把所有差异文件都收集到。无论是 LintGlobalTask 或者是 LintPerVariantTask,都继承自 LintBaseTask。最终的扫描任务在LintGradleExecution的runLint方法中执行,这个类位于 lint-gradle-26.1.1 中,前面提到这个库是基于 Lint 的 API 针对 Gradle 任务做的一些封装。
在这个方法中看到了warnings = client.run(registry),这就是 Lint 扫描得到的结果集。总结一下这个方法中做了哪些准备工作用于 Lint 扫描:
-
-
- 创建 IssueRegistry,包含了 Lint 内建的 BuiltinIssueRegistry;
- 创建 LintCliFlags;
- 创建 LintGradleClient,这里面传入了一大堆参数,都是从 Gradle Android 插件的运行环境中获得;
- 同步 LintOptions,这一步是将我们在 build.gralde 中配置的一些 Lint 相关的 DSL 属性,同步设置给 LintCliFlags,给真正的 Lint 扫描核心库使用;
- 执行 Client 的 Run 方法,开始扫描。
-
扫描的过程上面的原理部分已经分析了,现在我们思考一下如何构造增量扫描的任务。我们已经分析到扫描的关键点是client.run(registry),所以我们需要构造一个 Client 来执行扫描。一个想法是通过反射来获取 Client 的各个参数,当然这个思路是可行的,我们也验证过实现了一个用反射方式构造的 Client。但是反射这种方式有个问题是丢失了从 Gradle 任务执行到调用 Lint API 开始扫描这一过程中做的其他事情,侵入性比较高,所以我们最终采用继承 LintBaseTask 自行实现增量扫描任务的方式。
极牛网精选文章《Android 静态代码扫描效率优化与实践》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/9249.html
 微信公众号
微信公众号  微信小程序
微信小程序