起底 eBay Flink 的上云之路
阅读数:1057 2019 年 11 月 9 日 08:00

实时数据处理是当前数据生态的热门关注环节,是业务创新的重要前提。Flink从诞生之初就定位于实时计算的框架和引擎,演化至今,已经发展成为实时数据处理领域的佼佼者。然而,Flink 的使用门槛比较高,加上集群本身的维护和 job 状态管理并不容易,业务开发者们往往就会望而却步。事实上,我们仍有多种途径可以使 Flink 更加服务化、便捷化。
本文将分享我们在 eBay 内部如何提供Flink 服务的端到端管理,以解决业务开发者的后顾之忧,让他们专注于业务领域的创新,而无需烦心平台层面的维护。
从平台提供者角度,为了让 Flink 服务更触手可及并稳定可靠地运行,我们需要完整的组件来支撑。而云基础设施高度动态的运行时特征,也决定了平台需要具备更加弹性的机制来保证 Flink 集群的容错性和云原生特性。
一、集群生命周期管理
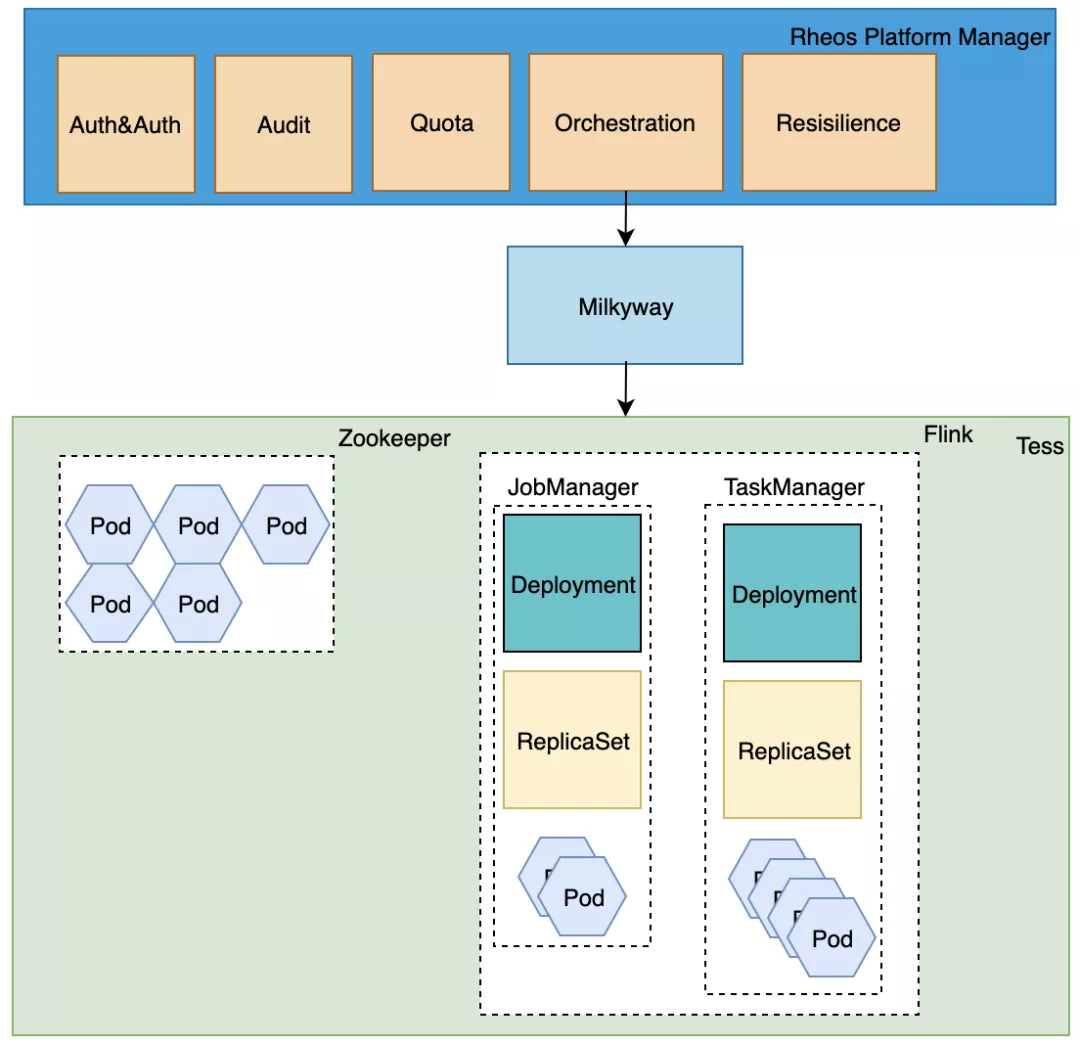
Flink 集群构建于Tess之上,Tess 是 eBay 对 Kubernettes 的定制和增强,是 eBay 内部使用的下一代云平台。我们采用Tess Deployment来构建 Flink cluster 的 TaskManager™和 JobManager(JM)。Deployment 的特性使得单个 Pod 即便因为各种原因被异常销毁或退出,也能被 Controler 自动带起,实现一定程度上的高可用和容错机制。JM的持续健康对集群至关重要,因为 JM 掌控着 job 的状态管理,以及统筹 job 的 checkpoint 机制。
为此,我们支持 JM 的 Active-Standby 架构,通过 Zookeeper 来实现主备之间的快速切换。
跟 Tess 交互,实现集群从构建、配置更改、伸缩扩展到销毁删除,这些过程涉及到复杂的元数据管理和事件处理。**NAP Service(MilkyWay)是 eBay 内部广泛使用的 Tess 应用管理平台,通过定义CRD(Custom Resource Definition)** 来管理应用的状态和组件之间的依赖,并提供接口以操作相应组件,此处可类比成 k8s 的 Operator。
Flink 集群的构建和维护正是依赖于Milkyway的这种能力,通过集成 Milkyway 接口,实现集群层面的生命周期管理,详见图 1。在这一过程中,我们设计实现了丰富的运维工作流,以支持不同业务场景下集群的演化和伸缩,这些工作流运行于 eBay 自研的工作流引擎 NAP Workflow 之上。
在 Flink 服务化的过程中,我们也构建了精细的权限管理和 Quota 管理,以实现不同租户(一个租户通常对应一个业务小组)之间资源的隔离性,同时避免资源竞争。此外,为保证服务的稳健性,我们也内建了自动重试机制和熔断机制。
平台构建的 Flink 集群运行于会话模式(Session Mode),意味着集群的生命周期与 job 的生命周期是互相独立的。这带来的好处是,允许 job 多次启停调试而无需重建集群,节省了集群频繁重建的耗时。同时,多个 job 能共用一个集群,也在一些场合下提升了资源利用率。
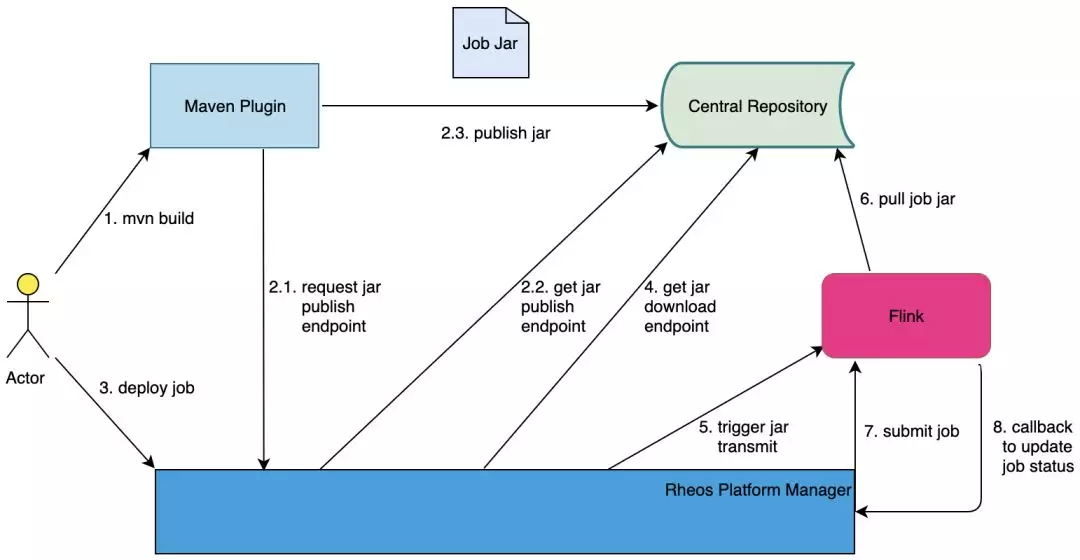
我们集成了 Flink 的 restful 接口来实现 job 的生命周期管理。通常情况下,在提交 job 之前,用户需要上传 job jar 包到 Flink 集群里,而后基于此 jar 包来提交 job 执行。另一方面,具备复杂业务逻辑且包含了依赖的 jar 包,通常都比较大。当增长到几百兆的大小时,本地上传 jar 包的体验就非常差,因为本地到线上集群的网络传输效率普遍较低,而本地到生产环境的集群甚至是隔离的。
为此,我们在 Flink 内部增强了jar 包管理模块,使得集群能从就近的存储系统主动下拉 jar 包到本地,而后基于此 jar 包提交任务。同时,我们还开发了一个maven 插件,当用户在项目中引用插件后,就能一键实现打包和上传 jar 包到存储系统。为了让提交到集群后的 job 和平台中维护的 job 元数据状态同步,我们在 Flink 端增强了一个回调机制,每次当 job 状态切换时,就会生成一个事件,而后这个事件会推送到平台端以更新元数据状态。
通过这些,用户就能在平台上一站式管理 job 的生命周期,详见图 2。
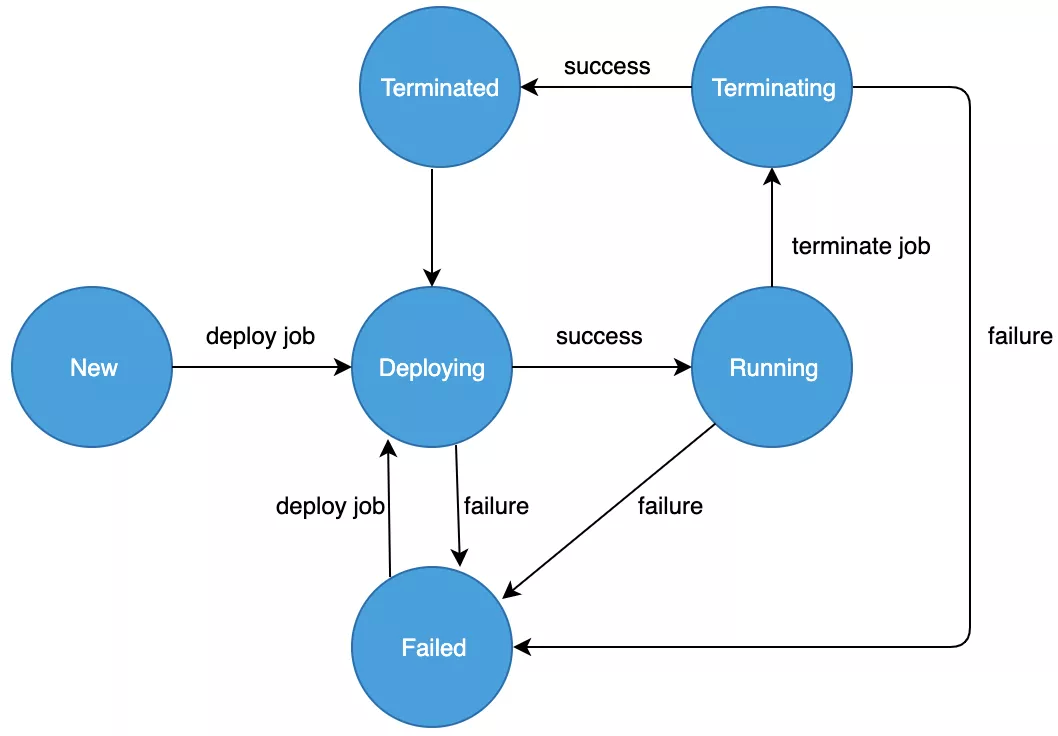
Flink 任务通常是一个长期无间断运行的流数据处理逻辑,但用户有时也会有临时中断 job 做参数调制或 debug 的需求。用户发起的 job 管理命令,经平台验证合法后,就会进一步下发到集群执行,job 状态迁移详见图 3。
Flink 原生支持 job 的 checkpoint 机制,通过定期给任务内部的状态数据打快照而实现 job 的容错能力。为实现高可用,这些快照数据都需要落盘存储到指定的集群内共享目录。然而,在云环境下,用户很难知道哪些目录可用。为此,我们设计实现了一系列的定制和增强,使得用户透明无感地享受到 job 的容错能力。
首先,我们为集群内的每个 Pod 以 local-volume 的形式挂载 Cephfs 到指定路径。
而后,我们定制了 Flink job 状态数据的管理机制,使得触发出来的 checkpoint 数据都能落到指定目录。
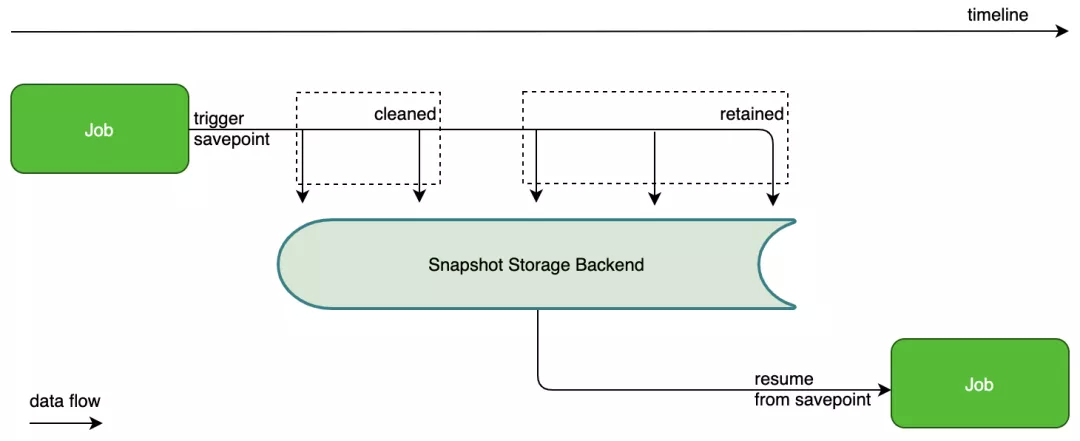
此外,我们还设计了合理的 Cephfs 目录结构,使得多租户环境下,同一租户建的集群之间能互通数据,而不同租户之间集群的数据互相隔离。Job 的 checkpoint 是由 Flink 运行时自动触发和管理的。而 savepoint 则由用户按需触发的状态数据保存方式,以便 job 下次启动时能达到断点续传的效果。我们在平台端实现了给 job 定期触发 savepoint 的功能,以便在碰到错误或需要 replay 数据的场景下,让 job 能穿梭到过去的任何时间点继续运行,详见图 4。为了避免 savepoint 数据膨胀,我们也引入了 retention 机制,以清理过期数据。
在云环境里,机器的维护和硬件故障是常态。因此,实时监控集群的健康状况,并配置异常告警系统就很有必要。
我们为 Flink 集群的各节点都内置了监控模块,以搜集节点本地的运行时特征。同时借助Prometheus收集各节点数据,汇聚成集群层面的健康指标,当探测到潜在风险时,及时通过 AlertManager 发出告警通知。节点和 job 的监控数据也同时发往 eBay 内部的统一监控平台,以便用户端查看指标报表和订阅异常告警。
人为处理异常告警是一项非常繁琐的运维工作,所以我们还搭建了一套智能运维系统以优化操作。当运维系统收到告警后,经过初检判断是否为假告警,而后根据先前积累的经验,采取一系列补救措施来把集群带回到健康状态。只有当运维系统无法处理或补救措施效果不明显时,系统才会将告警转发至管理员,由人工介入。
五、总结
把 Flink 服务化,让用户触手可得 Flink 特性,前端业务人员就能更加专注于业务逻辑本身,而无需关心平台以下的细节。这不仅优化了操作,节省了大量的时间和人力成本,更有助于 eBay 在风险监测、行为分析、数据洞察和市场营销等复杂案例上取得更多的业务创新和技术突破。
本文转载自公众号 eBay 技术荟(ID:eBayTechRecruiting)。
原文链接:
https://mp.weixin.qq.com/s/LeBYvP2uxQHY_RjF9D3ZqQ
技术管理电商最佳实践 评论 发布
极牛网精选文章《起底 eBay Flink 的上云之路》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/9436.html
 微信公众号
微信公众号  微信小程序
微信小程序 







