这是Python数据分析的第一个案例。它详细解释了TGI索引,并使用Python代码来实现基本的TGI偏好分析。
经常有一些专业的数据分析报告提到TGI指数,比如“基于这样那样的TGI指数,我们发现有些用户更喜欢XX”。对于不熟悉TGI定义的学生来说,看到类似的词语一定是云山雾罩。这次,让我们来谈谈什么是TGI指数,以及如何基于案例数据实现简单的TGI偏好分析。

内部事务不是由在线搜索决定的。对于TGI索引,百科全书是这样解释的——TGI索引,全称是目标群体索引(Target Group Index),可以反映特定研究范围内目标群体的强弱。
很好,官方的解释揭示了这个职业,这个职业充满了晦涩,晦涩的人似乎理解不了它。粗略翻译,TGI指数是反应偏好的指标。这还不够清楚,让我们来理解这个公式。
TGI指数计算公式=目标群体中具有某种特征的群体的比例/整个人口中具有相同特征的群体的比例*标准数字100
是否更令人眩晕?没错。我们还在谈论什么?在
01 指标拆解
TGI计算公式中,有三个关键点需要进一步分解:某个特征、人口和目标群体。
随便吃栗子。假设我们想研究甲公司脱发症的TGI指数:“某个特征是我们想分析的某个行为或状态。这里是脱发症(或患有脱发症)
人群是我们研究的所有对象,也就是公司的所有者
目标群体,这是我们对人群感兴趣的群体。假设我们专注于数据部门,那么目标群体就是数据部门。在公式中,分子“目标群体中具有一定特征的群体的比例”可以理解为“数据部门中脱发的比例”。假设数据部门有15人,9人患有脱发,数据部门脱发的比例为9/15,相当于60%。
分母“具有相同特征的群体在整体中的比例”相当于“整个公司脱发患者在公司总数中的比例”。假设公司共有500人和120人患有脱发症,比例为24%。
因此,数据部门的TGI脱发指数可按60%/24% * 100=250计算。其他部门TGI脱发指数的计算逻辑相同,本部门脱发百分比/公司脱发百分比* 100就足够了。
TGI指数大于100,这表明一些用户有更多相应的倾向或偏好。价值越高,倾向和偏好就越强。如果小于100,则表示此类用户的相关倾向较弱(与平均值相比);平均等于100意味着。
在刚才的例子中,我们撒谎的数据部门的TGI脱发指数是250,远远高于100。数据中脱发的风险似乎极高,数据是发际线的真正驱动力。
接下来,我们将通过一个案例研究巩固我们对这个概念的理解,顺便说一下,我们和熊猫大师谈过了。
项目背景
BOSS发送了一份详细的订单,“小Z,我们最近将推出一款客户名单相对较高的产品。我们将首先在一些城市进行试验。看看这些数据。城市里的人对高客户名单有偏好,帮我选5”。
02 TGI实例分析
Little Z快速打开表单,查看数据的样子:
订单数据包括品牌名称、买方名称、付款时间、订单状态和地区等字段。总共有28,832条数据,没有空值。
在粗略查看了一些源数据后,小Z很快明确了数据要求:“领导者,高客户列表的定义是什么?”
“从我们的产品线和历史数据来看,即使是高端客户,单次购买也比50元的多”。
在确定了高端客户名单后,我们的目标非常明确:根据高端客户名单的偏好对城市进行排名。这里的偏好可以用TGI指数来衡量。让我们再回顾一下TGI的三个核心点:“解决问题的关键在于计算不同城市高端客户的数量和比例。
单个用户打标
在第一步中,我们将首先判断每个用户是否属于拥有高客户列表的组,因此我们将首先根据用户昵称进行分组
Little Z快速打开表单,查看数据的样子:
接下来,定义一个判断函数。如果单个用户的平均支付金额超过50英镑,则标记为“高级客人列表”类别。否则,这是一个低客人名单。然后使用apply函数调用:
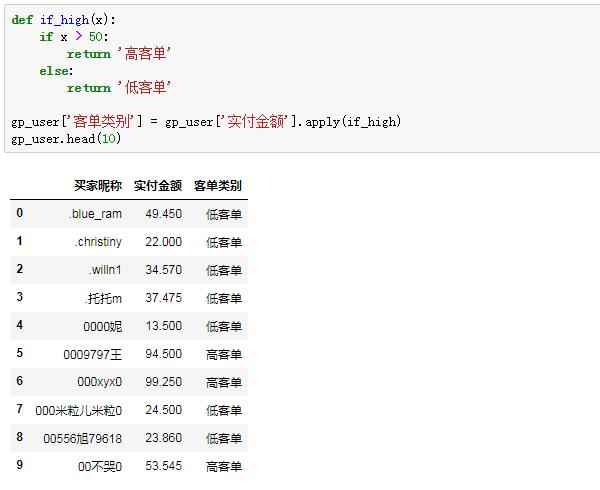 @
@
在这里,基于高低来宾列表的用户初始标记已经完成。
匹配城市
个人用户的数量和客人列表标签已修复。下一步是添加每个用户的区域字段,可以固定pd.merge函数。由于源数据没有经过重复数据消除,我们必须首先按昵称进行重复数据消除,否则匹配结果中会有许多重复数据:
高客单TGI指数计算
要计算个城市的高访客名单的TGI指数,我们需要分别获得每个城市的高访客名单和低访客名单的数量。如果您使用EXCEL的数据透视表来处理它,它非常简单。您可以将省市直接拖到行位置,将客户列表类别拖到列位置,并选择任何统计字段。
不要惊慌,Python很容易实现这组操作,pivot_table透视表函数可以在一行中完成:
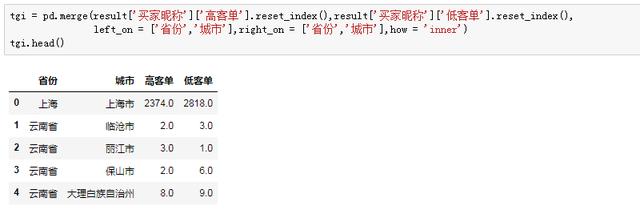
这样获得的结果包括分层索引,由于空间限制,这些索引不会被扩展。只要我们知道,为了索引“高客户名单”列,我们需要首先索引“买方昵称”,然后索引“高客户名单”:
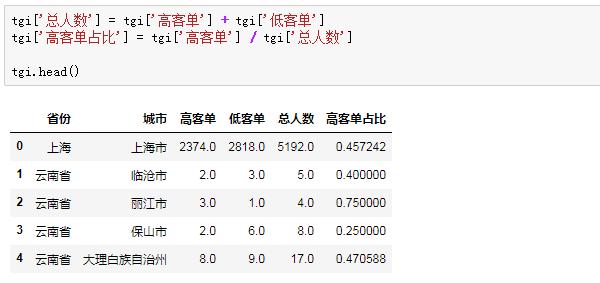
这样,我们就可以得到每个省市的高客户名单的数量。然后我们会得到低阶客户的数量并进行横向整合:
我们会查看每个城市的总数和高阶客户的比例来完成分子“目标群体中具有某些特征的群体的比例”的算:

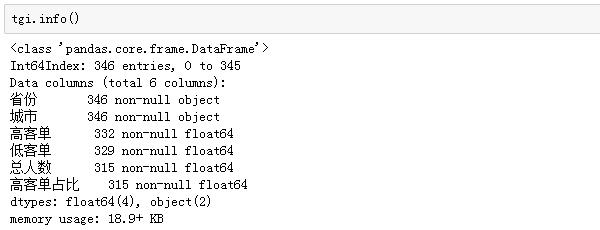
在一些非常小的城市中,高阶客户或低阶客户的数量等于1甚至不等于1,这些值,尤其是空值,会影响结果的计算。我们会提前检查数据:

果然。高访客列表和低访客列表都有空值(可以理解为0),导致总人数也有空值,而TGI指数对空值没有什么意义,所以我们删除了空值的行:
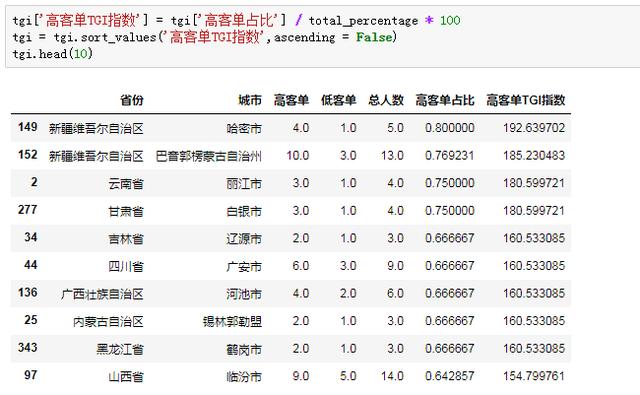
然后我们计算高访客列表人口在总人数中的比例,比较标准公式中分母“具有相同特征的组在整体中的比例:
最后一步是计算TGI指数,并对结果进行排序:
查看实用数据科学Python库文章,了解Python网络框架和网络服务器Python数据可视化之间的关系:boxmap的各种库表示使用Python来分析职位空缺,而Python的工资实际上排在最后。风筝的新版本:实时完成代码。
极牛网精选文章《Python数据分析必知必会:TGI指数》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/3556.html
 微信公众号
微信公众号  微信小程序
微信小程序 







