概述
MapReduce是谷歌提出的分布式计算模型,主要用于搜索领域,解决海量数据的计算问题。
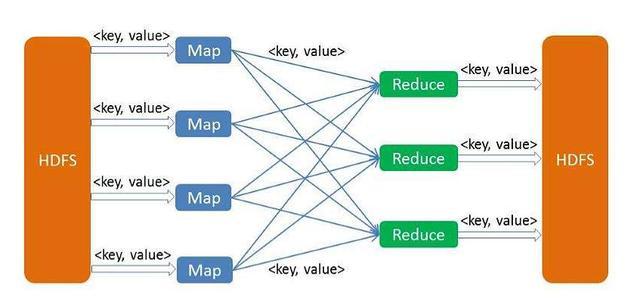
MapReduce是分布式的,由两个阶段组成:映射和缩减。映射阶段是一个独立的程序,多个节点同时运行,每个节点处理部分数据。
Reduce阶段是一个独立的程序,多个节点同时运行,每个节点处理部分数据。
使用
MapReduce框架有一个默认实现。用户只需要覆盖map()和reduce()函数来实现分布式计算,这非常简单。
这两个函数的形式参数和返回值都是,所以在使用它们时一定要注意构造。
1.获取每一个block块中的文本,遍历所有,回去其中的一行str
由于每个单词被计数的次数,仍然有必要根据字符串的特征找出文本中哪些单词可以使用split()进行剪切。

执行流程(此处举例说明)
文本中每个单词的出现次数(保存在HDFS,两个块
根据要求,我需要将每个单词转换成一种形式,k是单词本身,v是单词出现的次数。
2.因为mr的计算是分布式的 ,每一个map(称之为一个mapper task)计算其中的一个block块数据。
完成上述操作后,系统将向用户输出计算结果。通常,计算结果将被存储(着陆)到hdf,然后反馈给用户。
到目前为止,已经执行了MapReduce,然后可以执行一系列其他大数据操作。
极牛网精选文章《简单的介绍一下大数据中最重要的MapReduce》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/3768.html
 微信公众号
微信公众号  微信小程序
微信小程序