如果您是一名经验丰富的操作和维护开发人员,您必须了解ganglia、nagios、zabbix、elasticsearch、grafana和其他组件。这些开源组件有着深刻的开发背景和功能价值,但它们需要合理的配置和选择,以及如何匹配资源来实现性能,这反映了运营商的深层能力。“
接下来,联通大数据平台维护团队将介绍几种常见的监控组合,并根据丰富的实战经验,系统总结集群主机及其接口机的监控。
一、科普篇:几种常见的监控工具选择
当前常见的监控组合如下:
Nagios Ganglia Zabbix Telegraf或收集influxdb或普罗米修斯或弹性搜索Grafana警报管理器
Nagios、Ganglia和Zabbix是较早的开源监控工具,而grafana和prometheus则是冉冉升起的新星。下面将分别介绍三种监控报警模式的背景、优缺点:
1. Nagios+Ganglia
Nagios于1999年首次以“网圣”(NetSaint)的身份发布。主要用于监控Linux和Unix平台环境下的告警,可以监控网络服务和主机资源,并具有并行服务检查机制。
它可以自定义shell脚本以发出警报。然而,nagios逐渐无法满足使用场景,因为越来越多的服务和数据由大数据平台承载。例如,它没有自动发现功能,需要修改配置文件。只能在终端配置,不方便扩展,可读性差。时间控制台功能弱,插件不容易使用。没有历史数据,只能给出实时报警,出错后很难追踪故障原因。
Ganglia是由加州大学伯克利分校发起的开源监控项目,旨在测量数千个节点。神经节的核心包括gmond、gmetad和网络前端。主要用于监控系统性能,如cpu、内存、硬盘利用率、输入输出负载、网络流量等。通过曲线可以很容易地看出每个节点的工作状态,这对合理调整和分配系统资源,提高系统整体性能具有重要作用。然而,随着服务和服务的多样化,ganglia只覆盖有限的监控区域,定制配置监控更麻烦。神经节的主要缺点是难以在显示页面上找到主机以及显示图像粗糙和不准确。
2. Zabbix
Zabbix是近年来兴起的一种监控系统。易于启动,可实现基本监控。然而,深层需求需要非常熟悉Zabbix,并进行大量的二次定制开发,这是相当困难的。此外,系统级别的警报设置相对较多,如果不过滤,将会有许多警报邮件。此外,用户定义的项目警报需要自行设置,这相当复杂。
3. jmxtrans or Telegraf or collect + influxdb or Prometheus or elasticsearch + Grafana +alertmanager
该监控系统具有数据采集、存储、监控、显示和报警的优点。性能、功能可扩展性和积极的社区支持。缺点是它的功能是松散耦合的,这测试了用户对使用场景的判断以及操作和维护能力。毕竟,对于操作和维护系统来说,没有“* * *”,只有“最合适的”。
早期,中国联通的大数据平台有效地将ganglia与nagios相结合,充分发挥ganglia的监控优势和nagios的预警优势,从而监控平台的各项指标。然而,随着大数据服务的快速增长和平台的日益复杂,nagios和ganglia开始对平台的监控有点不足,开发成本太高。主要体现在繁琐的配置上,不容易上手;监控和收集脚本的开发过于分散,无法以统一的方式进行管理。nagios没有历史数据,只能实时向警方报告。犯错后很难找到失败的原因。
中期,我们在一些集群中使用了zabbix,发现其对集群层、服务层、角色层和角色实例监控项的多维监控、开发和管理相对复杂,如果我们想将平台上所有机器和服务的监控和报警集成到zabbix上,这将是对zabbix性能的巨大挑战。
因此,我们采用了以普罗米修斯格拉瓦纳警报管理器为核心组件的监控和报警方法来构建和开发,以完成对现有大规模集群和h
二、实战篇:平台搭建、组件选型、监控配置的技巧
1. 采集、存储工具的选型
常见的收集器包括collect、telegraf和jmxtrans(公开jmx端口的监控服务)。经过比较,笔者选择了telegraf,主要是因为它相对稳定,并且得到了InfluxData公司的支持。社区活动良好,插件版本的更新周期不会太长。Telegraf是一个用Go语言编写的代理程序,可以收集系统和服务的统计数据,并将它们写入InfluxDB、prometheus等数据库。Telegraf具有内存占用小的特点。通过插件系统,开发人员可以轻松地添加扩展来支持其他服务。
(2)数据库选择
对于数据库选择,作者* * *使用influxdb。在此过程中,应注意调整和增加influxdb的并发性,并控制数据的存储周期。对于成千上万台服务器的群集监控,如果存储在influxdb中,当通过grafana接口查询时,将生成大量线程来读取influxdb数据,并且在读取和写入influxdb数据时可能会遇到很长的超时时间。
在这种情况下,您可以首先检查副本存储策略:在tele上显示保留策略
然后修改副本存储的周期:
远程嫁接上的备用策略“自动增长”持续时间72h复制1碎片持续时间24小时默认
您需要了解以下参数:
持续时间:持续时间。0表示* * * ShardGroupDuration:ShardGroup的存储时间,这是InfluxDB的基本存储结构,大于此时间的数据的查询效率会降低。ReplicaN:全名是RePublic,默认副本数:它是默认策略吗@
但是,由于influxdb开源版本对于分布式支持的不稳定性,influxdb服务器的单机版本对于成千上万个服务器监视器(用于数据存储的普通sata磁盘,而不是ssd)具有性能瓶颈。作者后来选择使用专家系统或promethaus联邦来解决这个问题(专家系统的相关权限控制、构建、优化、监控和维护,以及promethaus的相关解释将在随后的文章中详细阐述)。
2. Grafana展示技巧
Grafana是近年来流行的监控配置显示工具。它的优点是可以与各种主流数据库接口,在官方网站和社区下载精致的模板,并通过导入json模板快速显示数据。
(1)主机监控项目
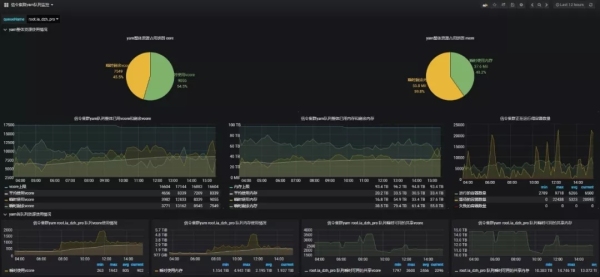
主机监控项目概述:内核、内存、负载、磁盘IO、网络、磁盘存储、索引节点占用率、进程数、线程数。主机监控大屏幕:以主机监控显示为例,让我们先看看效果图。
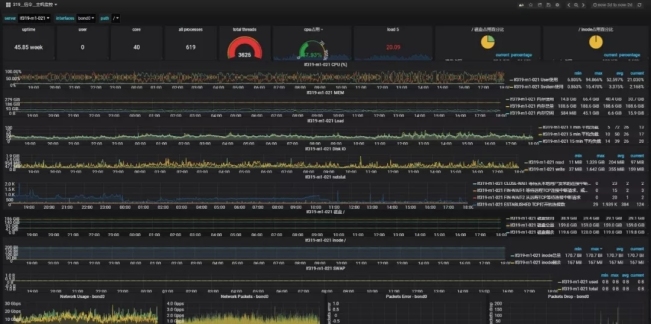

主机使用分类:作为一家专业的大数据服务运营商,联通的大数据公司在后台支持大量主机,每台主机的使用都非常不同,所以有必要做好主机分类工作。使用盒子的概念,计算机房是父类盒子,其中放置集群计算节点子盒子和接口机器子盒子。群集主机和接口计算机是分开的,因此当主机出现故障时,查找和定位既方便又快速。
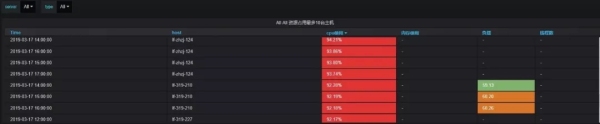
主机资源占用率前10:占据同一主机组最多资源的前10台机器主要从cpu占用率、内存占用率、负载和线程数等维度进行统计(如机房接口机为主机组,计算节点为主机组)。
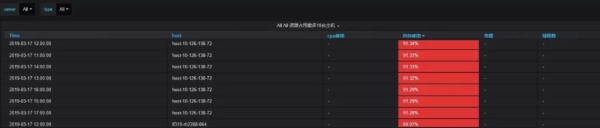

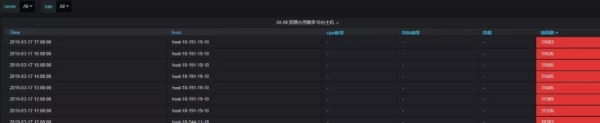
进程资源占据前10名:主机监控大屏幕,主机资源占据前10名,定位故障主机的故障时间段和异常指标,这只能初步帮助操作和维护人员调查机器故障的原因。例如,当机器上的负载过高时,主机的cpu使用率通常可以在主机的大监视器屏幕上看到,读写io和网络io会迅速增加,但无法找到是哪个进程导致的。当故障主机重新启动时,无法调查历史故障的原因。因此,对于主机级监控,进程资源占据的前10位增加,进程信息(有用信息,如进程开始运行时间、运行时间、进程pid、cpu利用率、内存利用率等)。)占用cpu和内存* * *可以获得。这样,当主机运行未经测试的程序,或者运行太多程序,或者有太多并发程序线程时,它可以通过历史数据有效地定位机器故障的原因。

摘要:主机级别仍有许多监控项目。关键是对症下药,将故障排除的操作和维护经验转化为合理的数据收集过程,并通过数据关联对故障进行分析和故障排除。
平台监控项目种类繁多,包括hdfs、纱线、动物园管理员、卡夫卡、暴风、星火、hbase等平台服务。每个服务下有不同的角色类别,如hdfs服务中包含的名称节点、日期节点、故障转移控制器和日志节点。每个角色类别下有多个实例。有成千上万个这样产生的监测指标的例子。联通大数据目前使用的CDH版大数据平台具有全面多样的基本监控指标。根据目前的情况,我们主要在平台层面配置一些关键的监控项目。
簇纱队列资源占用多维纵向:帮助平台经理合理评估队列资源的使用情况,并快速做出适当调整。
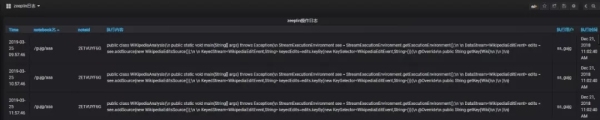
zeeplin操作日志:zeeplin没有相关的可视化审核日志。实时获取塞普林操作日志,显示普林操作情况,便于操作维护人员审核。
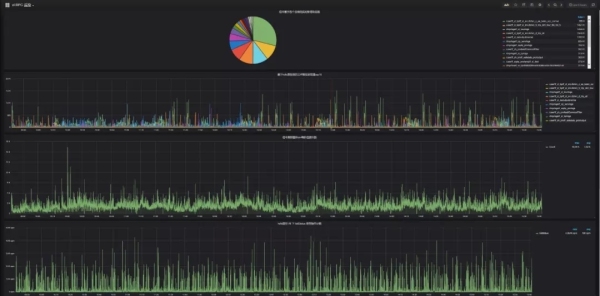
hdfs目录文件计数和多维纵向存储:实时统计各种业务用户的数据目录存储,便于分析hdfs存储增量过大的目录。

Cluster namenode RPC实时多维纵向:当hadoop集群节点的数量达到约1,000个时,集群服务使用80%以上的纱线队列资源,而集群写入多于读取少,这很容易导致namenode-rpc等待队列深度过大,并导致namenode-rpc延迟,这将严重影响整个集群服务的运行。半小时内可以完成的任务可能会运行几个小时。根本原因是集群承载了太多的服务,业务逻辑设计不合理,导致线程任务执行过程中hdfs文件系统频繁运行,导致大量rpc操作。在较低级别,每个dn节点的磁盘负载也将过高,导致数据读写io超时。你赢得了数据科学家容易犯的十个编码错误吗?操作和维护监控的秘密,设置它!人工智能专家:大数据知识地图——实战经验总结20个安全可靠的免费数据源。您可以从所有数据字段中进行选择,以解决在线数据库中的死锁问题。就这么简单!
通过提取名称节点日志、hdfs审计日志和多维分析,可以通过hdfs目录和hdfs操作类型确认操作过多的rpc操作。并根据具体的操作类型过多,来分析业务逻辑是否合理,以进行业务优化。例如,大型数据服务的逻辑是每秒将数千个文件写入hdfs目录,每秒遍历hdfs目录。但是,触发处理每十分钟触发一次,因此该服务会生成大量rpc操作,这会严重影响群集性能。调整后,通过每五分钟遍历一次hdfs目录,群集性能得到了极大的优化。
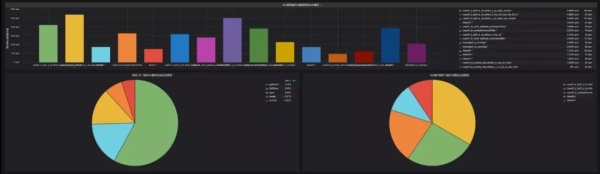
(3)日常生产监控项目
生产报告:由于联通大数据平台承载了大量的业务,后台查询繁琐,而可视化显示可以方便生产运维人员快速了解日常生产情况,定位生产延迟的原因。
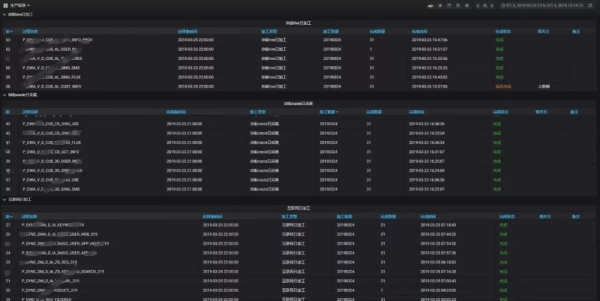
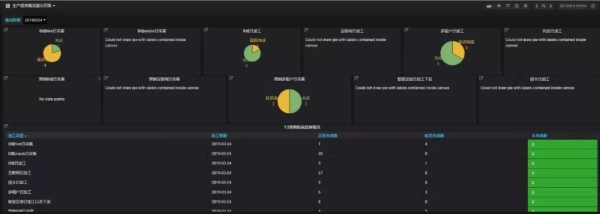
结论:本文首先介绍了平台监控的内容。在接下来的文章中,笔者将对平台报警进行经验分享,并介绍如何建立统一的采集模板、报警各集群的总监控指标、群组报警和自动恢复等。
极牛网精选文章《大数据平台监控宝典(1):联通大数据集群平台监控体系进程详解》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/4064.html
 微信公众号
微信公众号  微信小程序
微信小程序 