前言
数据表(Data.table)是r语言中非常常见的高性能包,使用简单、方便、快捷。它在r语言社区非常流行,每月下载超过400,000次,近650个CRAN和Bioconductor软件包使用它。如果您是r的用户,您可能已经使用了data.table包。
对于Python用户,还有一个名为datatable的包,它侧重于大数据支持、内存/内存不足的高性能数据集和多线程算法。在某种程度上,数据表在Python中可以称为data.table。
MAC操作系统Linux系统@
为了更精确地构建模型,现在机器学习应用程序通常需要处理大量数据并生成各种特性,这已经变得很有必要。然而,Python的数据表模块为解决这个问题提供了很好的支持,并以可能的最大速度在单节点机器上执行大数据操作(高达100GB)。数据表包的开发由H2O赞助,其第一个用户是无人驾驶,ai
2.1 安装
安装过程需要通过二进制分发来实现。
不幸的是,数据表包目前无法在视窗系统上工作,但是Python官员也在努力增加对视窗的支持。有关更多信息,请参见构建说明的说明。
2.2 数据读取
此处使用的数据集是来自卡格尔竞赛的贷款俱乐部贷款数据集,其中包含2007-2015年期间所有贷款人的完整贷款数据,即当前贷款状态(当前、延迟、全额付款等)。)和最新的支付信息等。整个文件包含226万行和145列数据。数据量非常适合演示数据表包的功能。
数据集:
首先将数据加载到Frame对象中。数据表的基本分析单元是框架(Frame),这与熊猫数据框架(Panands DataFrame)或SQL table的概念相同:数据以行和列的二维数组显示。
使用数据表读取数据
该数据集有226万行、145列和近1.2G的数据。只有2.54s
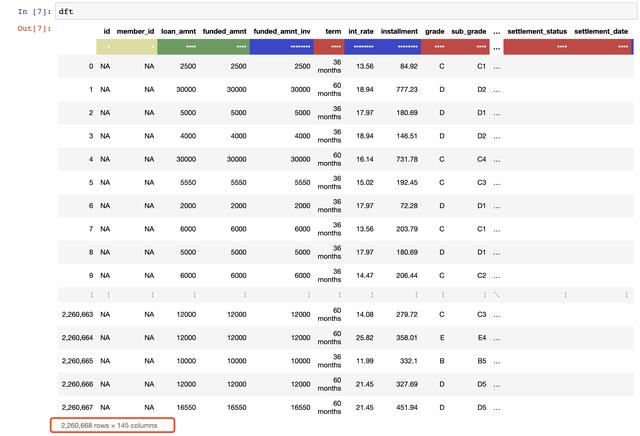
用于通读数据表。如上所示,fread()是一个强大而快速的函数,可以自动检测和解析文本文件中的大多数参数。支持的文件格式包括。压缩文件、网址数据、电子表格文件等。此外,数据表解析器有以下主要功能:
可以自动检测分隔符、标题、列类型、引用规则等。能够读取各种文件的数据,包括文件、网址、外壳、原始文本、文件、全球等。多线程文件读取功能提供最大速度。读取大文件时包含进度指示器。可以读取RFC4180兼容和不兼容的文件。使用熊猫读取数据@
注: 由于数据量大,与熊猫一起阅读数据通常会导致服务中断。因此,数据量稍小的数据集可以用来测试
As。由此可见,在读取大数据时,数据表包的性能明显优于熊猫。熊猫需要将近30秒来读取这些数据,而数据表只需要超过2秒。
2.3 帧转换 (Frame Conversion)
对于当前存在的帧,可以将其转换为Numpy或Panands数据帧,如下所示:
接下来,将数据表读取的数据帧转换为Panands数据帧,并比较所需时间。如下所示:
由于借贷俱乐部贷款数据数据集中有大量数据,所以使用to_padnas操作很容易挂起jupyte服务,因此使用较小的数据集进行测试。
通过数据表读取数据并将其转换为数据帧数组,总计2.62毫秒。
单独通过熊猫读取数据,总计14.4毫秒。
与直接读取熊猫数据帧相比,将文件作为数据表帧读取并转换为熊猫数据帧所需的时间似乎更少。因此,通过数据表包导入大数据文件,然后将它们转换成熊猫数据帧是个好主意。
2.4 帧的基础属性
以下描述了数据表中帧的一些基本属性,这类似于熊猫中数据帧的一些功能。
您也可以使用head命令打印输出数据的前N行,如下所示:
注意:这里使用颜色表示数据类型,其中红色表示字符串,绿色表示整数,蓝色表示浮点。
2.5 统计总结
在熊猫中,汇总和计算数据的统计信息是一个非常消耗内存的过程,但这个过程在数据表包中非常方便。如下所示,使用数据表包计算以下每一列的统计数据:
使用数据表和熊猫计算每一列数据的平均值,并比较两者在运行时的差异。
数据表读取熊猫读取@
使用熊猫计算时抛出内存错误时出现异常。
Datatable简介
像dataframe一样,datatable也是一种列数据结构。在数据表中,所有这些操作的主要工具是方括号,受传统矩阵索引的启发,但它包含更多的函数。例如矩阵指数、碳/碳、碳、熊猫、核物理都使用同样的数学表示。让我们看看如何使用数据表来做一些常见的数据处理工作。
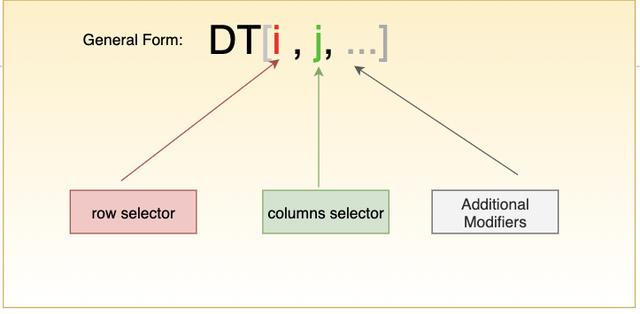
选择行/列的子集
下面的代码可以从整个数据集过滤掉所有行和financied _ amnt列:
显示了如何选择数据集中前5行和3列的数据,如下所示:
帧排序
datatable 排序
通过数据表中的特定列对帧进行排序,如下所示:
Pandas 排序
您可以看到两个包之间排序时间的明显差异。
删除行/列
以下显示了如何删除列成员_id中的数据:
分组 (GroupBy)
与熊猫相似,数据表也有一个GroupBy操作。让我们来看看如何通过在数据表和熊猫中分组等级来获得资助金额列的平均值:
数据表组熊猫分组
.f 代表什么
在数据表中,F代表frame_proxy,这提供了一种引用当前操作框架的简单方法。在上例中,dt.f仅代表dt_df。
过滤行
在数据表中,筛选器行的语法与GroupBy非常相似。下面显示了如何过滤掉loan_amnt中大于financing _ amnt的值,如下所示。
保存帧
在数据表中,帧的内容也可以通过将其写入csv文件来保存,以便以后使用。如下图所示:
有关数据操作的更多功能,请参见数据表包
数据操作
在数据科学领域,数据表模块比默认的熊猫包执行速度更快,这是它在处理大型数据集时的主要优势之一。然而,就功能而言,数据表包中包含的功能并不像熊猫那样完美。我相信在不久的将来,不断改进的数据表将会更加强大。
极牛网精选文章《媲美Pandas的数据分析工具包Datatable》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/3568.html
 微信公众号
微信公众号  微信小程序
微信小程序