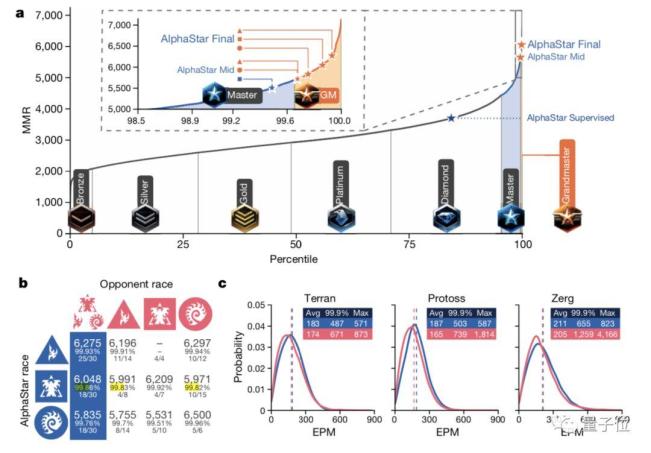
只有0.2%的星际争霸2玩家没有被人工智能击败。
这是阿尔法星(AlphaStar),他匿名进入梯子,并交出了最新的成绩单。
与此同时,DeepMind在《自然》上充分披露了阿尔法星(AlphaStar)目前的能力和全套技术:
阿尔法星已经超过了人类玩家的99.8%,在神族、人族和虫族种族中已经达到特级大师的水平。
在论文中,我们还发现了特殊的训练姿势:
DeepMind在他的博客中说,AlphaStar在《自然》上发表了四个主要的更新:
首先,约束:人工智能的视角现在和人类的一样,对运动频率的限制更加严格。
第二,人族神族虫族可以是1v1,每个种族都有自己的神经网络。
第三,联盟训练是完全自动的,从监督学习的代理开始,而不是已经强化学习的代理。
四是战网的结果。阿尔法星在所有三场比赛中都达到了大师级别。它使用与人类玩家相同的地图。所有比赛都可以回放。
就人工智能的学习过程而言,深度思维(DeepMind)强调特殊的训练目标设定:
并非每个代理人都追求获胜面的最大化。
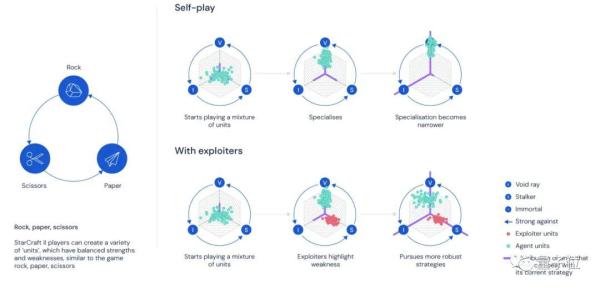
因为在自我游戏(Self Play)的过程中,代理很容易陷入某种策略,这种策略只有在某些情况下才有效,而且在面对复杂的游戏环境时,性能会不稳定。
所以,团队指的是人类玩家的训练方法,即与其他玩家一起进行有针对性的训练:一个代理可以通过自己的操作暴露另一个代理的缺陷,这可以帮助另一个玩家练习一些想要的技能。
因此,有不同目标的代理人:第一个是主要代理人,其目标是获胜,第二个负责利用主要代理人的缺点帮助他们变得更强,而不是专注于提高他们的获胜率。DeepMind称之为第二个“剥削者”,我们简单地称之为“拳击”。
AlphaStar学到的各种复杂策略都是在这个过程中培养出来的。
例如,蓝色是主要玩家,负责获胜,红色是帮助它成长的同伴。萧红发现了小蓝未能抵挡的加农炮冲锋技能:
接着,一名新的主要玩家(吕霄)学会了如何成功抵挡萧红的加农炮冲锋技能:
同时,吕霄通过经济优势击败了前主要玩家小蓝。以及单位组合和控制:
后面跟着另一个新的训练伙伴(肖布朗),他发现了主要玩家肖格林的新弱点,并用隐藏的刀子击败了它:
cycling,AlphaStar变得越来越强大。
至于算法的细节,这次完全显示出来了。
许多现实生活中的人工智能应用涉及复杂环境中多个代理之间的竞争和协调。
对星际争霸这样的即时战略游戏的研究是解决这个大问题过程中的一个小目标。
也就是说,星际争霸的挑战实际上是多智能体强化学习算法的挑战。
阿尔法星(AlphaStar)学习玩星际游戏,还是依赖于一个深层神经网络,它从原始游戏界面接收数据(输入),然后输出一系列指令,在游戏中形成一定的动作。
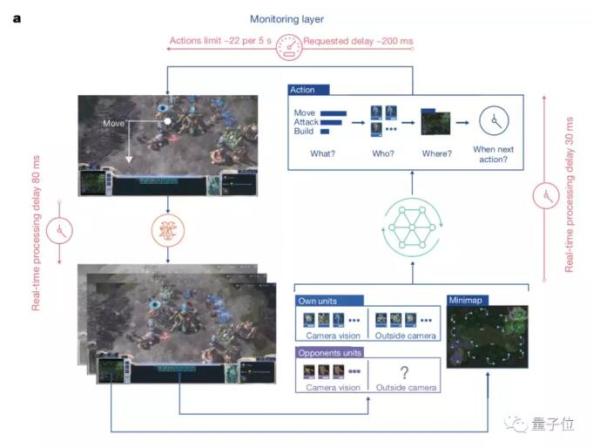
AlphaStar将通过概览地图和单位列表观看游戏。
在采取行动之前,智能将输出要采取的行动类型(例如构建)、行动将应用于谁、目标是什么以及何时采取下一个行动。
动作将通过限制动作速率的监控层发送到游戏中。
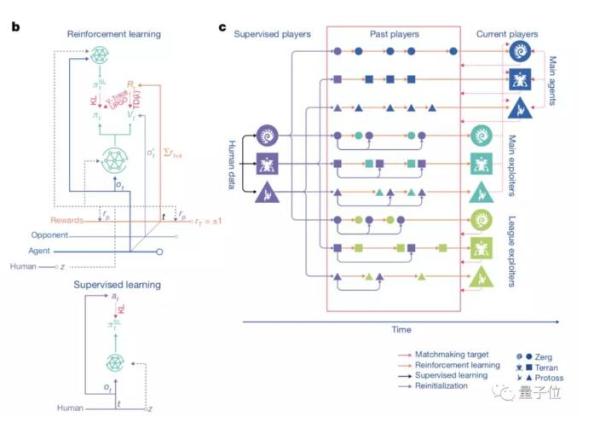
培训通过监督学习和强化学习完成。
起初,训练是有监督的学习,材料来自暴雪发布的匿名人类玩家的游戏。
这些材料使阿尔法星能够通过模仿星际迷航玩家的操作来学习游戏的宏观和微观策略。
游戏中内置的原始代理(the Elite)人工智能可以被击败,相当于人类的黄金等级(95%)。
这个早期的代理是强化学习的种子。
在此基础上,创建了一个连续联盟,这相当于为代理人准备一个竞技场。竞技场上的特工是彼此的对手,就像人类在梯子上互相竞争一样:
如果从现有的代理创建新的分支,将会有越来越多的玩家加入竞争。新代理商从与竞争对手的竞争中学习。
这种新的培训形式深化了以前基于人口的强化学习思维,创造了一个可以持续探索巨大战略空间的过程。
这种方法不仅可以确保代理人在对手面前表现出色,而且不会忘记如何对付以前不太强的对手。
随着代理联盟的继续,当新的代理诞生时,新的反策略似乎将处理早期的游戏策略。
新代理执行的一些只是早期策略的略微改进版本;代理的另一部分可以探索全新的策略、完全不同的构建顺序、完全不同的单元组合和完全不同的微操作方法。
此外,应该鼓励联盟中代理的多样性,因此每个代理都有不同的学习目标:例如,代理应该针对哪些对手,以及应该使用哪些内部动机来影响代理的偏好。
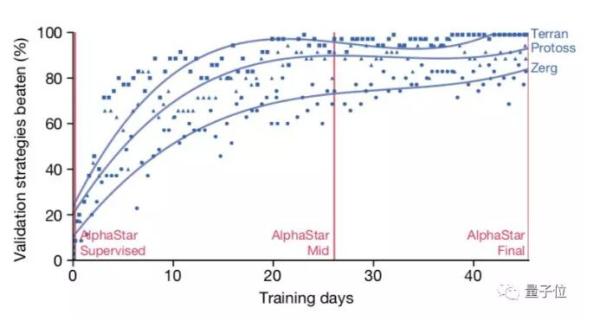
联盟培训的稳健性
此外,代理的学习目标将适应不断变化的环境。
神经网络给每个智能体的权重也随着强化学习的过程而变化。不断变化的权重是学习目标演变的基础。
权重更新规则是一种新的非策略强化学习算法,包括经验重放、自模仿学习和策略提炼等机制。
《星际争霸》,作为最具挑战性的即时战略游戏之一,不仅需要协调短期和长期目标,还需要应对意外情况,这一直是人工研究的“试金石”。
因为它面临着一个不完美的信息游戏局面,挑战非常艰巨,研究人员需要花很多时间来克服这些问题。
DeepMind在推特上说阿尔法星可以达到目前的结果。研究人员已经研究《星际争霸》系列游戏15年了。
但是DeepMind的工作确实是众所周知的,也就是这两年。
2017年,AlphaGo击败李世石两年后,DeepMind和暴雪联合发布了一套名为PySC2的开源工具。在此基础上,结合工程和算法的突破,进一步加快了星际游戏的研究。
从那以后,许多学者也对星际争霸进行了许多研究。例如,来自南京大学、腾讯人工智能实验室、加州大学伯克利分校等的余洋团队。
今年1月,阿尔法星迎来了阿尔法围棋。
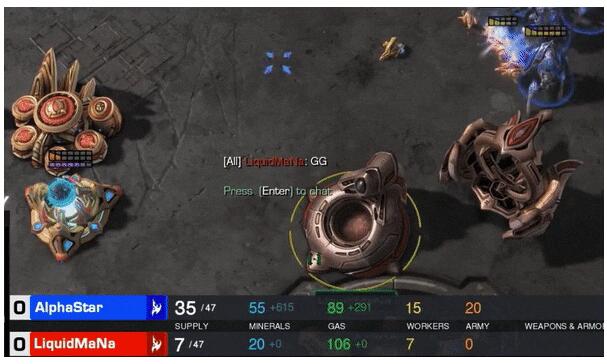
在与星际争霸2职业玩家的比赛中,阿尔法星(AlphaStar)以10-1的总比分统治了比赛。人类职业玩家液体魔法值(LiquidMaNa)只在它面前坚持5分36秒,然后是GG。
全能职业选手TLO在落败后哀叹与阿尔法星的竞争非常困难,不像和人玩,他感到不知所措。
半年后,阿尔法星再次经历进化。
DeepMind已经完全控制了神族、人族和虫族,并解锁了许多地图,同时保持其APM(手速)和视觉与人类玩家一致。

同时,它宣布了最新进展:阿尔法星将登陆游戏平台Battle.net,匿名匹配梯子。
现在,随着最新论文的发布,阿尔法星(AlphaStar)的最新能力也发布了:它击败了99.8%的玩家,赢得了大师称号。
DeepMind在他的博客中说,这些结果提供了强有力的证据,证明通用学习技术可以扩展人工智能系统,使其在涉及多个参与者的复杂而动态的环境中工作。
随着星际争霸2取得如此辉煌的成绩,DeepMind也开始专注于更复杂的任务。
CEO哈萨比斯说:“15年来,《星际争霸》对人工智能研究人员来说是一个巨大的挑战,所以看到这项工作被《自然》杂志认可是非常令人兴奋的。
这些令人印象深刻的成就标志着向目标——迈出了重要的一步,目标——是创建一个能够加速科学发现的智能系统——。
那么,DeepMind接下来要做什么?
Hassabis还多次表示星际争霸“只是”一个非常复杂的游戏,但他对阿尔法星背后的技术更感兴趣。
但是有些人认为这项技术非常适合军事用途。
然而,从谷歌和DeepMind的态度来看,这项技术将更加注重科学研究。
其中包含的超长系列预测,如天气预测和气候建模。
也许你最近对这个方向并不陌生。
由于谷歌刚刚意识到的量子优势,最潜在的应用方向也是气候等大问题。
现在量子计算已经取得了重大突破,深度思维人工智能走得更远。
未来更值得期待。你说什么?
虽然阿尔法星取得了巨大的成就,但仍有一些人无法赢得它。当阿尔法星第一次进入梯子时,人类恶魔之王塞拉(Serral)公开嘲笑它。只是为了好玩。

但是这个家庭确实有实力,现在他们仍然可以正面对抗人工智能。然而,世界上只有一位大师敢这样说话。
极牛网精选文章《碾压99.8%人类对手,星际AI登上Nature,技术首次完整披露》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/3084.html
 微信公众号
微信公众号  微信小程序
微信小程序