
《面向神经机器翻译的篇章级单语修正模型》 [1]是一部关于文本级神经机器翻译的作品。针对文本级双语数据的不足,本文讨论了如何利用文本级单语数据来提高最终性能,并提出了一种基于目标侧单语的文本级修订模型(DocRepair)来修订传统的句子级翻译结果。

1,背景
近年来,神经机器翻译发展迅速。谷歌在2017年提出的变压器模型[2]极大地提高了翻译质量,在某些领域达到了与人类相当的水平[3]。然而,今天的大多数机器翻译系统仍然基于句子层次,不能利用文本层次的上下文信息。如何在机器翻译过程中有效利用文本级信息是当今的研究热点之一。
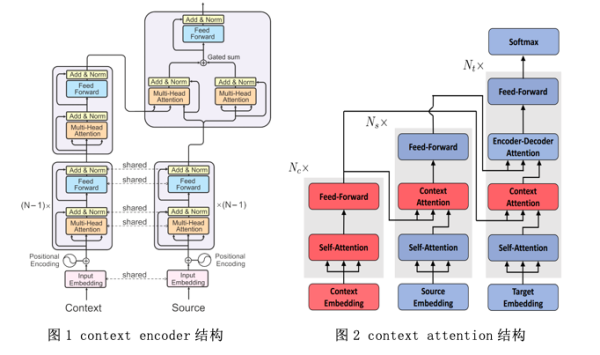
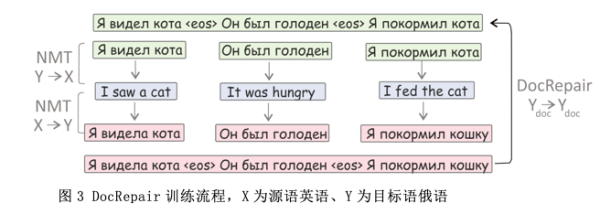
由于基于自注意机制的Transformer模型被广泛应用于机器翻译任务中,许多以前基于RNN机器翻译模型的文本级方法不再适用。最近,许多研究者试图通过在编码或解码阶段引入上下文信息来改进变换器。沃伊塔等人[4]首先提出了一个基于变压器模型的文本级翻译模型(图1)。除了传统模型之外,还添加了一个上下文编码器来编码上下文信息,然后将上下文信息与当前句子的编码结果融合并发送到解码器。张家诚等人[5]采用了另一种方法,分别向编码器和解码器添加上下文注意子层(图2)来引入上下文信息。一些研究人员试图先使用两遍模型[6][7]进行句子级解码,然后通过结合句子级解码结果和源语言上下文编码,使用文本级解码器进行文本级解码。此外,一些研究探讨了什么样的语境信息应该被引入文本级翻译。
上述工作在机器翻译过程中引入了语境信息,并将文本级翻译视为一个整体过程。这种建模方法更自然,但它需要足够的文本级双语数据进行培训。然而,在实践中很难获得文本级双语数据。作者提出了DocRepair模型来解决文本级双语数据稀缺的问题。
类似于两阶段方法,DocRePure模型也是对句子级结果的修正,但不同之处在于DocRePure模型只需要单语数据。作为单语序列对序列模型(seq2seq),DocRepair模型需要将上下文不一致的句子组映射到一致的结果,以解决上下文不一致的问题,如图2所示。

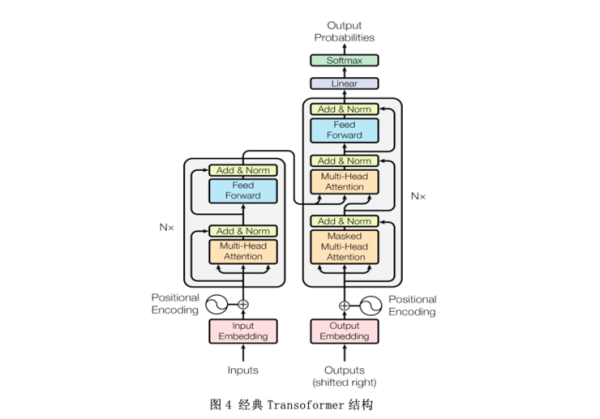
模型的训练语料库来自容易获得的文本级单语语料库。单语数据中上下文一致的句子组作为模型输出,往返法构造的上下文不一致的句子组作为模型输入。往返分为两个阶段,需要正向和反向翻译系统。首先,使用逆向翻译模型将目标端的文本级单语数据翻译到源端,得到句子间上下文信息丢失的源语言结果。然后,使用前向翻译模型将源语言结果翻译回目标端,以获得上下文不一致的目标端数据。整个过程如图3所示。
DocRepair型号采用标准变压器结构(图4)。模型输入是不包含上下文信息的句子序列,并且通过分离标记连接成长序列。模型输出是一个具有一致上下文的修改序列,最终结果是通过移除分离标记获得的。由
作者提出的结构可以被看作是一个独立于翻译模型的自动后编辑系统,其最大的优点是只有目标单语数据可以用于构建训练集。相应地,该方法引入了额外的结构,增加了整个系统的复杂性,并且使得训练和推理成本更大。同时,DocRepair模型可能没有充分考虑上下文信息,因为根据翻译结果只校正了目标端,根本没有引入源端信息。先前的工作也证实了源端上下文信息在文本级机器翻译中的作用,以及如何使用源
为了验证该方法的有效性,作者从BLEU、文本级专用测试集和人工评估的角度进行了对比实验。这项实验是在英俄任务中进行的。数据集使用开放数据集开放字幕2018。
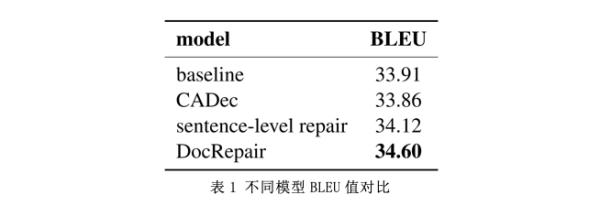
表1是DcoRepair的对比实验结果。其中,基线采用Transformer base模型,CADec[7]是一个两阶段文本级翻译模型。同时,为了验证DocRepair模型在文本级翻译中的有效性,不仅因为句子的后编辑提高了翻译质量,还训练了句子级修复模型。可以看出DocRepair在文本级机器翻译中是有效的,比句子级修复模型高0.5 BLEU,比基线和CADec高0.7 BLEU。
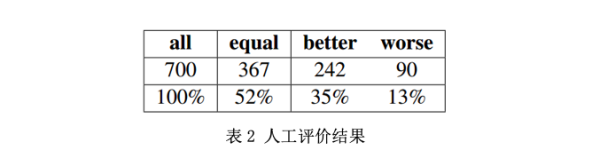
manual evaluation使用了公共测试集中的700个样本,不包括DocrePair模型完全复制输入的情况。如表2所示,52%的样品用相同质量手工标记,其余73%的样品被认为在DocrePair输出中具有更多优势,这也证实了模型的有效性。
为了分析DocRepair对文本级翻译中特定问题的有效性,作者在专门为英语和俄语文本级翻译现象构建的数据集[9]上进行了验证,结果如表3所示。指示语代表句子之间的回指问题,lex.c代表文本中实体翻译的一致性,ell.infl和ell。动词短语分别对应于名词形式和动词省略,它们包含在源端,但不包含在目标端。
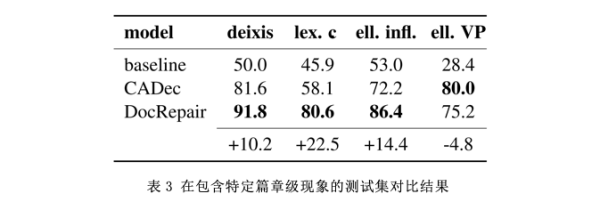
在指称、词汇选择和名词形式省略方面有明显优势,而在动词省略方面,DocRepair模型比CADec低5%。可能的原因是DocRepair模型只依赖于目标单语,而往返法构建的训练集很少包含缺失的动词样本,这使得模型很难做出正确的预测。
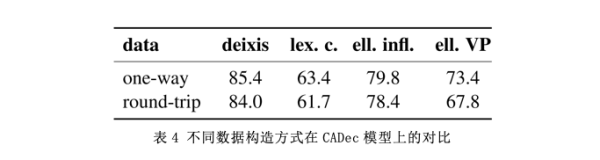
为了验证单语数据的局限性,作者在DocRepair模型上进行了不同数据构建方法的对比实验,结果见表4。单向表示在双语数据中用源语言代替往返的第一个反向过程。从整体上看,单向模式高于双向模式,双向模式最难的问题是动词省略。
本工作提出了一个完全基于目标单语的文档修复模型,用于纠正机器翻译结果和解决文本层面的不一致性。同时,分析了数据存储对在特定文本级问题中的性能,指出了仅依赖单语数据和双向构造的局限性。
以前的工作主要集中在如何在解码过程中融合上下文信息,但是性能经常受到文本级双语数据不足的限制。这项工作为我们提供了一个避免双语数据稀缺的新思路,但也提出了一个新问题。文本级翻译的目标是解决传统句子级翻译中句子间语境信息丢失的问题。然而,在这种后编辑方法中,只有在目标端没有上下文一致性的一组翻译结果可以用于通过单语校正模型获得一致的结果,该模型缺乏对源语言的关注。作者认为,在双语稀缺的情况下,如何更好地引入源语言语境信息也是一个有趣的问题。
极牛网精选文章《面向神经机器翻译的篇章级单语修正模型》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/3246.html
 微信公众号
微信公众号  微信小程序
微信小程序 





