Kafka 创建背景
卡夫卡(Kafka)是一个最初由领英开发的消息系统,用作领英活动流和运营数据处理管道的基础。现在,它已经被许多不同类型的公司用作各种类型的数据管道和消息系统。

活动流数据是几乎所有网站在报告其网站使用情况时最常用的数据部分。活动数据包括页面视图、关于正在查看的内容的信息以及搜索结果。处理这类数据的通常方法是将各种活动以日志的形式写入一些文件,然后定期对这些文件进行统计分析。操作数据是指服务器的性能数据(中央处理器、输入输出使用、请求时间、服务日志等)。)。操作数据有多种统计方法。
近年来,活动和操作数据处理已经成为网站软件产品功能的重要组成部分,需要稍微复杂一点的基础设施来支持。
Kafka 简介
卡夫卡是一个分布式的、基于发布/订阅的消息传递系统。主要设计目标如下:
以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间复杂度的访问性能。 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒 100K 条以上消息的传输。 支持 Kafka Server 间的消息分区,及分布式消费,同时保证每个 Partition 内的消息顺序传输。 同时支持离线数据处理和实时数据处理。 Scale out:支持在线水平扩展。
Kafka 基础概念
概念一:生产者与消费者
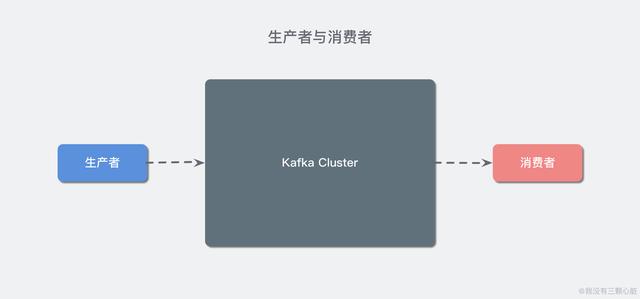
对于卡夫卡来说,有两种基本类型的客户:生产者和消费者。此外,还有高级客户端,如用于数据集成的卡夫卡连接应用编程接口和用于流处理的卡夫卡流。然而,这些高级客户端的底层仍然是生产者和消费者应用编程接口,它们只封装在顶层。
很容易理解生产者(也称为发布者)创建消息,而消费者(也称为订阅者)负责消费或阅读消息。
概念二:主题(Topic)与分区(Partition)
在卡夫卡中,消息是按主题分类的,每个主题对应一个“消息队列”,有点类似于数据库中的一个表。然而,如果我们将所有同类消息放入“中央”队列,将不可避免地缺乏可伸缩性。无论生产者/消费者的数量增加还是消息的数量增加,系统的性能或存储都可能耗尽。
让我们用生活中的一个例子来说明:现在甲市生产的商品需要通过公路运输到乙市,那么在“甲市商品较多”或者“现在丙市也需要将商品运输到乙市”的情况下,单行道公路就会出现“吞吐量不足”的问题。因此,我们现在引入了分区的概念,它以类似于“允许建造更多道路”的方式水平扩展了我们的主题
概念三:Broker 和集群(Cluster)
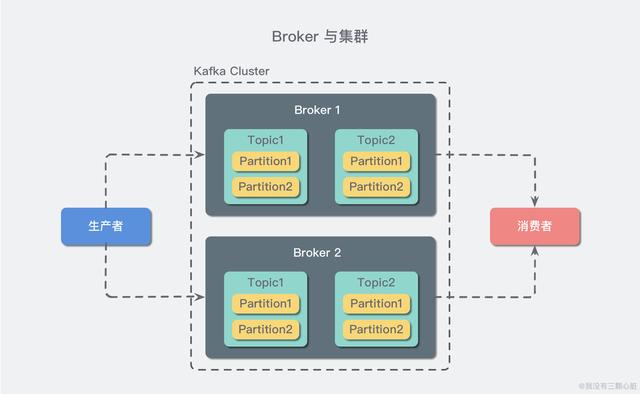
卡夫卡服务器,也称为经纪人,接收制作人发送的消息并将其存储在磁盘上;Broker还服务于消费者请求提取分区消息并返回到目前为止已经提交的消息。使用特定的机器硬件,代理每秒可以处理数千个分区和数百万条消息。(目前,它总是在一百万左右。我特地去查了一下。对于集群,吞吐量似乎相当高。压.)
多个代理组成一个集群,集群中的一个代理将成为集群控制器,负责管理集群,包括为代理分配分区、监控代理故障等。在群集内,分区由代理管理,代理也称为分区的领导者。当然,一个分区可以复制到多个代理以实现冗余,这样当代理出现故障时,它的分区可以被重新分配给其他代理来接管。下图是一个示例:
卡夫卡的关键属性是日志保留。我们可以为主题配置消息保留策略,例如只保留一段时间的日志,或者只保留特定大小的日志。超过这些限制时,旧邮件将被删除。我们还可以为某个主题单独设置一个消息过期策略,以便为不同的应用程序实现个性化。
概念四:多集群
随着业务的发展,我们通常需要多个集群,原因通常如下:
 多数据中心(灾难恢复)
多数据中心(灾难恢复)
当建立多个数据中心时,通常需要实现消息互通。例如,如果用户修改个人数据,无论哪个数据中心处理后续请求,都需要反映更新。或者,来自多个数据中心的数据需要聚合到一个通用控制中心进行数据分析。
上述分区复制冗余机制仅适用于同一卡夫卡集群。对于多个卡夫卡集群的消息同步,可以使用卡夫卡提供的MirrorMaker工具。本质上,MirrorMaker只是一个卡夫卡式的消费者和生产者,由一个队列连接。它消耗来自一个集群的消息,然后向另一个集群生成消息。
极牛网精选文章《学习Kafka,先从这四个基础概念入手》文中所述为作者独立观点,不代表极牛网立场。如有侵权请联系删除。如若转载请注明出处:https://geeknb.com/3592.html
 微信公众号
微信公众号  微信小程序
微信小程序 







